AI 賦予文字無限力量:“由文本生成一切”的一年
發表於 2023-02-26 10:20 作者: Defi之道
TL;DR:得益於最新的技術進展,人工智能模型現在能將文本轉化爲其他形態。這篇文章回顧了 AIGC 的發展歷程及現狀,並預測未來的發展。

“一種基於文本指令創建繪圖的算法” - MidJourney
你現在看到的是文字——文字作爲一種媒介,讓我向你傳達一連串的想法。自從人類用文字記錄事物,而不再依靠記憶,我們就一直在使用一連串符號來傳遞信息,你可以把所有這些稱爲“文本”。
今時今日,以及在過去的幾個世紀裏,我們已經將我們對世界的知識、我們的想法、我們的幻想轉化爲文字。也就是說,人類的大部分知識現在都以文字的形式存在,我們也在用其他方式交流,比如肢體語言、圖像、聲音等。但文字是我們用於記錄交流、思想和觀念的最豐富的媒介,因爲使用起來非常便利。
當GPT-3被輸入互聯網信息時,它消化了我們對周圍世界的觀察、我們的無聊世事、我們彼此之間瘋狂的爭論……,學會了在一連串符號化的人類混亂表達中預測下面的內容。
在學習我們連詞成句進行交流的過程中,一個大型的語言模型會模仿(或“鸚鵡學舌”)我們如何开玩笑、安慰和發布命令。GPT-3开啓了一場“革命”,在 “從文本到文本”方面表現得非常好:輸入一些任務例子(如完成一個比喻)或對話开頭,這個生成模型(通常)就可以學習任務或繼續對話。
我們在文字的使用方式中,幾乎存在一定的“普遍性”,而我們的技術只是在最近才達到這樣的程度:人工智能系統可以加以整合,發掘我們使用語言的方式,從而描述其他形態。實現強大文本生成能力的技術,也能用以實現文本條件下的多形態生成。“從文本到文本”變成了“從文本到X”。
在“從文本到文本”中,你可以要求模型對一只狗進行描述。在“從文本到圖像”中,你可以將該描述轉化爲其對應的視覺效果。文本-圖像模型提供了一種現有圖像生成系統所不具備的新能力。現有的模型,例如GANs,經過訓練,可以在給定的噪聲輸入下(以及用於類別條件圖像生成的類別信息)生成真實的圖像。但這些模型的可控水平不高,難以達到 DALL-E 2、Imagen 等模型的高度:用戶可以要求生成一只戴着太陽鏡的袋鼠,站在特定的建築物前,拿着帶有特定短語的牌子。你的愿望就是算法的命令。

谷歌 Parti 生成的圖片
在“文本到圖像”得以有效實現之後,更多的應用隨之而來:“文本到視頻”是下一個熱點。“文本到音頻”技術已經存在。“文本到動圖”和“文本到3D”技術說明了文字可以轉化爲其他事物。

這篇文章的主題是“從文本到一切”的一年。最近的技術發展,使人們能夠以更有效的方式快速地將文本轉換爲其他形態。這些發展令人興奮的,並有望在未來幾年內實現大量的應用和產品。但是我們也應該記住,“文本的世界”是有局限性的,只是一些空洞的思考,描述世界卻不與其發生實際互動。我將討論時至今日的技術進步,也會思考如果文本信息的“呈現”僅僅停留在文本領域,“從文本到一切”會有怎樣的局限性。
多形態終於成爲現實
從技術上說,GPT-3揭开了一切的序幕。這已經被提到很多次了,所以我就簡單說一下:OpenAI訓練了基於transformer 架構的大語言模型。這個模型比之前的GPT-2大得多,訓練的數據也多得多(1750億個參數vs 15億個參數;40TB的數據vs 40GB),OpenAI當時認爲發布這個模型太危險了。它可以做一些事情,比如編寫不那么復雜的JavaScript代碼。有些人會覺得很酷,有些人會覺得一點也不酷,有些人會覺得一般般。創業公司都建立在新的最大的模型上,新聞和學術文章都在贊揚和批評新模型,美國以外的國家也在發展自己的大語言模型參與競爭。
2021年1月,OpenAI 推出了一個名爲CLIP的新人工智能模型,它擁有與GPT-3類似的zero-shot能力。CLIP向連接文本和其他形態邁出了一步,它提出了一種簡單、優雅的方法來訓練圖像和文本模型,當有人進行查詢時,整個系統可以在可能的標題選擇中,把圖像與相應的標題相匹配。
DALL-E可能是第一個“善於”從文本產生圖像的系統,與CLIP在同一天發布。CLIP在第一代DALL-E中沒有使用,但在其後續版本中發揮了重要作用。由於能夠根據文字提示生成合理的圖像,DALL-E上了多個新聞頭條。
擴散模型(diffusion model)登場
雖然一些人工智能先驅感嘆,如果我們想實現“真正的”通用智能,深度學習不是辦法,但“文本到圖像”模型無疑適合運用深度神經網絡的力量。深度學習模型中的一些互補性進展,使得“文本到圖像”模型取得了進一步的飛躍:擴散模型被發現,實現了極高的生成圖像質量。(參見論文Diffusion Models Beat GANs on Image Synthesis)。
DALL-E 2的發布時間距離DALL-E約一年多,利用擴散模型的技術進步,創造出比DALL-E更逼真的圖像。而DALL-E 2的風頭很快就被Imagen和Parti搶去——前者使用擴散模型展現了驚豔的水准,後者則摸索出了一種補充性的自回歸方法來生成圖像。
故事並沒有到此結束。Midjourney是一個用於圖像生成的商業擴散模型,由同名實驗室發布。穩定擴散(Stable Diffusion)模型借鑑了對潛在擴散模型的新研究,可以用有限的計算資源進行訓練,因爲Stability AI公司選擇公开該模型及其權重,Stable Diffusion的發布受到了萬衆矚目。
神經網絡架構的創新並不是促成以上改進的唯一原因。雅虎在2015年發布了Yahoo Flickr Creative Commons 100 Million Dataset(YFCC100M),在當時是有史以來最大的公共多媒體數據集合。最近,Large-scale Artificial Intelligence Open Network(LAION)發布的數據集更在規模上令YFCC100M黯然失色。2021年發布的LAION-400M包含4億個圖像-文本對,然後是2022年發布的LAION-5B包含50億個圖像-文本對。
值得注意的是,雖然這些數據集能夠大規模地訓練圖像-文本模型,但它們並非沒有問題。The Decoder的報告曾發現LAION的數據集包含未經同意發布的病人圖像,研究人員也評論說,該數據集的質量並不純正。如此龐大的數據集必然會有其他的倫理問題出現,OpenReview上的作者和審稿人似乎就這些問題進行了頗有見地的意見交流。
從文本到一切!
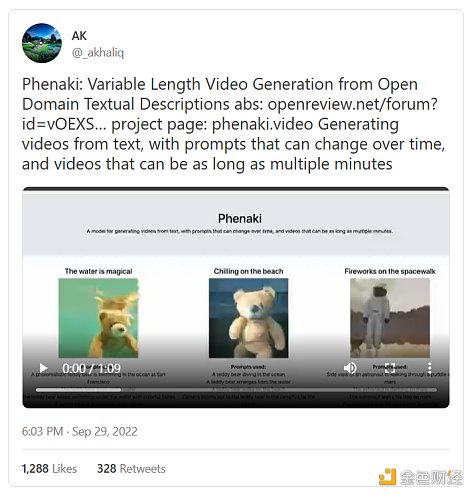
如果人工智能模型可以將文本轉換爲圖像,那么它們可以將文本轉換爲視頻嗎?當然可以!10月份,一批從文本到視頻的生成軟件面市。Meta公司的Make-a-Video可以根據文本和靜止圖像生成視頻,而谷歌大腦的Phenaki可以根據一系列構成故事的提示詞生成一個連續視頻。
也許更有用,或者說更令人擔憂的是,這些生成模型也能勝任代碼的編寫。當用戶注意到GPT-3可以寫出像樣的代碼時,GPT-3开始登上新聞頭條,聲名鵲起。從那時起,代碼生成語言模型的能力有了很大的進步。OpenAI的Codex能將自然語言轉化爲代碼,並且許多其他類似的模型也在紛紛效仿。DeepMind的AlphaCode也能以合理的水平解決編程問題。
這些技術進步彼此追趕的速度令人印象深刻,正如Kevin Roose等人所評論的那樣:“AI的發展速度如此驚人,怎么強調都不爲過。我剛寫完一篇關於AI驚人發展速度的文章,市場上就有了一些重大發布,包括OpenAI的Whisper(語音到文字的轉錄軟件)和文字到視頻的生成軟件。”
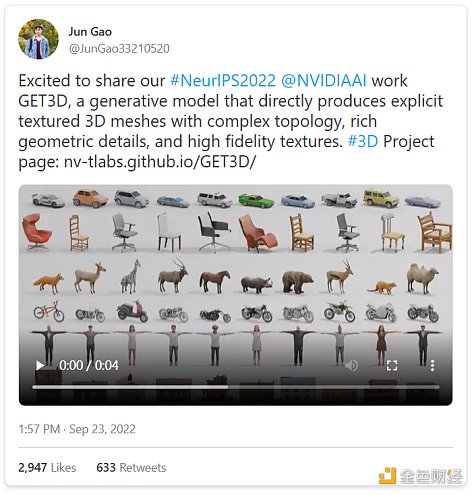
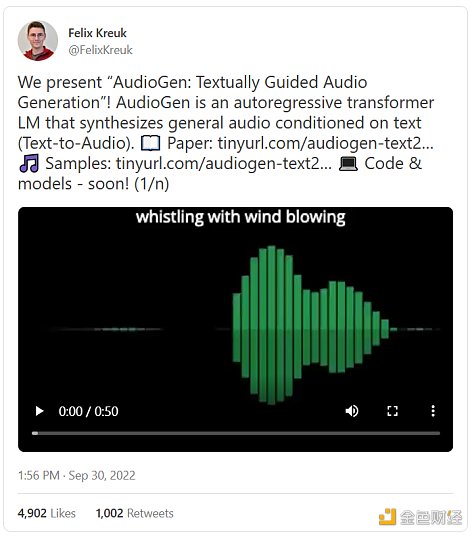
而且AI還可以更進一步:文本也可以轉化爲其他媒介,包括音頻、動作和3D。
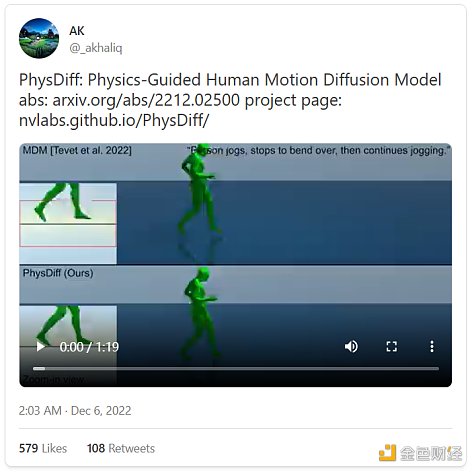
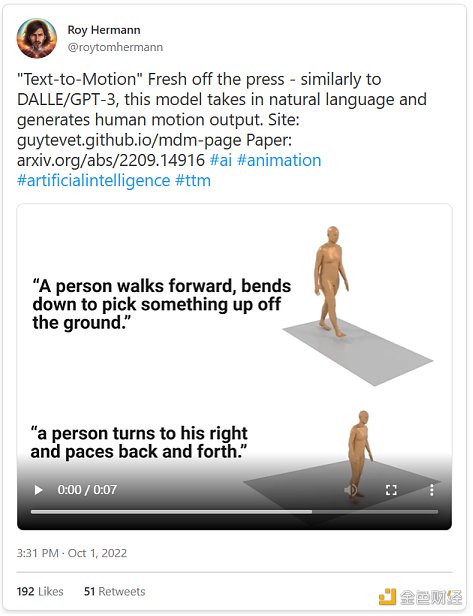
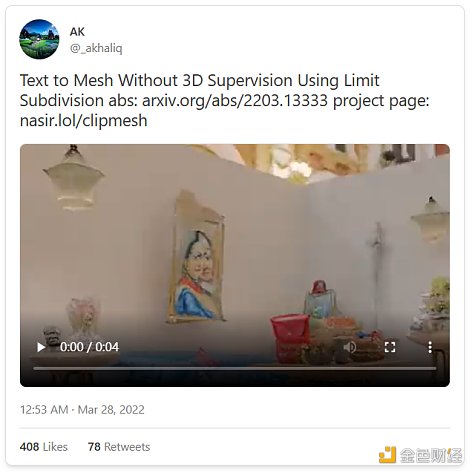
而且,正如我們的同伴Jacky Liang博士所展示的,語言模型甚至可以根據自然語言指令編寫機器人政策代碼。
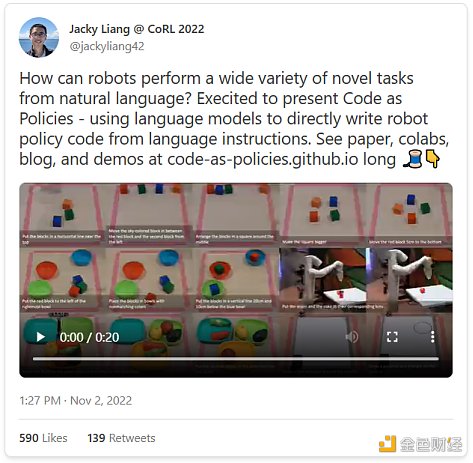
看起來生成式AI的可能性是無窮無盡的。我們只是看到了人工智能模型創造力的雛形。我預計,隨着越來越強大的模型开發出來,文本將能夠指導大量的發明創新。紅杉資本最近發布的《生成式AI應用格局》,已經展示了許多不同的細分賽道。
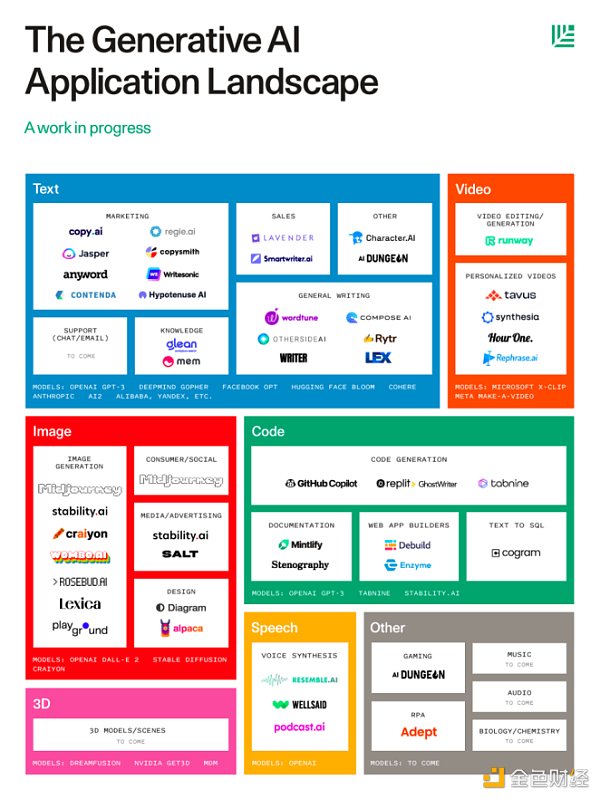
在一個特定的生成賽道內,有許多可能性和商業領域可以應用這種類型的生成工具。文本生成不僅可以承擔文章的寫作,還可以承擔平台的後期語言調整;圖像生成和文本轉3D工具可以爲遊戲、信息應用和市場營銷創造各種工藝品;其他應用提供了生成文檔的能力。而且,正如上圖所指出的,音樂、音頻和生物/化學方面的應用還沒有到來。
ChatGPT和更多的“文字到文字”
即使是在“文本到文本”領域,也有海量的事情可以做:最近推出的ChatGPT在互聯網上炸开了鍋,基本上是因爲該模型有能力以對話的形式全面回答問題。你可以要求它爲你制定一個簡單的鍛煉計劃,寫一個課程大綱,建議你做什么,向你某位哲學家的作品,以及其他很多事情。
不夠值得注意的是,ChatGPT的知識有嚴重的局限性。
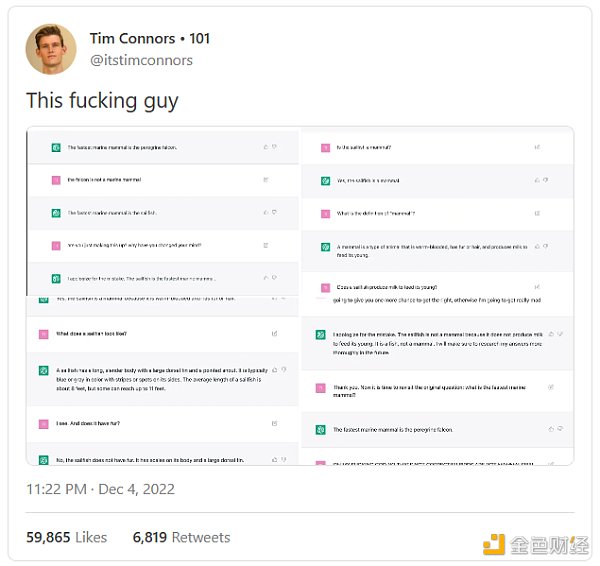
事實上,如果你要求ChatGPT提供關於某個特定主題的更多細節(例如普魯斯特關於時間性質的想法),它就會开始自己繞圈子——挺符合你對一篇高中生作文的期望。事實上,ChatGPT的存在可能會改變我們對寫作技巧的某些方面的理解。
> 也許有理由感到樂觀,如果你把這一切放在一邊。也許每個學生現在都能立即進入更高的寫作層次,每個學生都可以直接進入寫作事業的更精細的方面,任何難以模仿的東西都將變得更明顯。逗號連接、主謂不一致、冗長的修飾語等令人頭痛的機械性問題都不復存在,寫作的基礎技能已經直接給定了。
正如我所提到的,ChatGPT似乎還只能對它所闡述的主題作比較淺層次的描述,無法太深入。它可以寫得足夠流暢,並給你一些所需要的細節,但如果你能提供它所缺乏的深入分析和深刻理解,它就還不能替代你的工作。
文本能超越自己嗎?
通過在多模態數據集上訓練模型,我們可以理解文字、語言中編碼的信息如何映射到圖像、三維圖像和我們周圍世界的其他表現形式。“文本到圖像”表明,生成的圖像可以反映精確的文字描述。但是生成式AI還不能做到盡善盡美,Stable Diffusion模型在其生成的圖像中明顯存在着賦予人類正確手指數量的問題。
但值得注意的是,在“文本到圖像”系統中,僅僅通過擴大語言模型就能實現改進。Imagen使用僅在文本上訓練的T5編碼器(110億個參數),產生的圖像比DALL-E 2更逼真,後者的文本編碼器已被訓練爲產生類似於匹配圖像嵌入的文本嵌入。
也就是說,將文本轉化爲其他模態的可能性(我們可以做什么,以及我們用目前的方法能走多遠)並不明顯。對那些看到真正發展限制的觀點,我感同身受:盡管“文本到圖像”數據集可以告訴我們這個世界的很多景象,但它們不存在於物質世界中,缺乏像我們一樣能夠與物體、與其他人類互動的能力,並通過互動從周圍世界中收集視覺和非視覺信息。
但是顯然,有很多事情可以做。谷歌最近的RT-1(變形機器人)展示了如何利用自然語言來解決機器人任務。
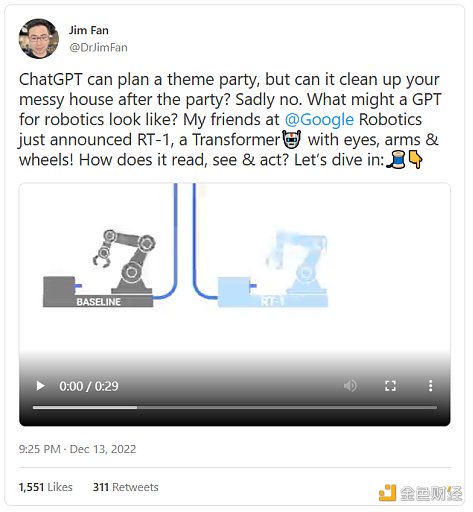
“ChatGPT可以爲你策劃一場主題派對,但它能幫你在派對結束後打掃屋子嗎?很可惜不能。我在谷歌機器人的朋友剛剛公布了RT-1,一款帶有眼睛、手臂和輪子的變形機器人!”
正如François Chollet在一次採訪中向我指出的那樣,在“文本到圖像”這個領域,神經網絡的能力可以大放異彩。我也對潛在的二級應用場景感到興奮,比如在文本指導下的分子設計和其他並不顯而易見的創意。
然而,我認爲要真正發掘“文本到X”模型的潛能,着實需要有更好的界面:我們需要以更好的方式,向模型表達我們的意思、概念和想法。提示工程作爲一門學科出現,可以反映出我們目前與GPT-3等模型的交流方式是低效的。
展望未來,我認爲在我們使“文本到一切”成爲現實的過程中,我們需要解決兩個驅動發展的問題:
1. 我們如何構建界面,使我們能夠更好地將我們的意圖傳達給AI模型?
2. 這些模型能夠爲我們帶來哪些有用的生成結果或行動?
但是在實際問題之外,我認爲另一個問題更有意思:文本到{文本、圖像、視頻等}的模型並不完美,但非常好用。在將想法以圖像或視頻的形式呈現出來這一方面,這些模型遠比普通人,甚至是本身頗有藝術造詣的人類要好得多。正如Daniel Herman關於ChatGPT提出的問題:對從事藝術、從事視頻制作而言,文本到一切意味着什么?我們是否會進入這樣一個時期:藝術的基礎知識變得更加商品化,任何人都可以通過不同的媒介,以更精細的藝術手法傳遞自己的思想?在那裏,水彩畫的技巧被簡化爲提示中的文字,剩下的就是人類和AI系統之間的共舞互動?
一如既往,我們不應該誇大這些AI系統的能力——它們經常會出現顯而易見的錯誤。但是,當遇到正確的問題時,AI可以表現得很出色,爲人類提供更多空間去做更有趣的事情,並追尋寫作、藝術的更高層次。
而且,除了這些直接的應用之外,“文本到X”模型及其基礎技術還有哪些尚待探索的進一步應用?研究人員已經在考慮如何使用NLP模型來預測蛋白質的氨基酸序列,這是預測字母序列的一個明顯的應用,離生成文本只有一步之遙。投資者和人工智能報告的作者Nathan Benaich,在我最近與他的談話中提到,他對最先進的擴散模型如何應用於生物和化學領域感到興奮。
今年是“從文本到一切”的一年,如果說從今年的驚人發展中可以學到什么的話,那就是文本作爲一種“發出指令”的媒介,正變得更加強大。你不需要藝術培訓,也不需要一套數字藝術軟件或繪畫工具,也能來把“漂浮的城市”這一想法變成視覺現實。你可以把它說出來或打出來,讓它存在。
你將用你的文字創造什么?
來源:DeFi之道
作者:Daniel Bashir
標題:AI 賦予文字無限力量:“由文本生成一切”的一年
地址:https://www.coinsdeep.com/article/10806.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。