Dragonfly Capital 合夥人:去中心化推理的信任問題與驗證挑战
發表於 2024-03-29 18:37 作者: 金色精選
 免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
Dragonfly Capital 合夥人:去中心化推理的信任問題與驗證挑战

 金色精選
金色官方
剛剛
金色精選
金色官方
剛剛
 關注
關注
作者:Haseeb Qureshi,Dragonfly Capital 合夥人 來源:medium 翻譯:善歐巴,金色財經
假設你想要運行像 Llama2–70B 這樣的大型語言模型。如此龐大的模型需要超過 140GB 的內存,這意味着你無法在家用計算機上運行原始模型。你有什么選擇?你可能會跳到雲提供商,但你可能不太熱衷於信任單個中心化公司來爲你處理此工作負載並收集所有使用數據。那么你需要的是去中心化推理,它可以讓你在不依賴任何單一提供商的情況下運行機器學習模型。
信任問題
在去中心化網絡中,僅僅運行模型並信任輸出是不夠的。假設我要求網絡使用 Llama2-70B 分析治理困境。我怎么知道它實際上沒有使用 Llama2–13B,給我提供了更糟糕的分析,並將差額收入囊中?
在中心化的世界中,你可能會相信像 OpenAI 這樣的公司會誠實地這樣做,因爲他們的聲譽受到威脅(在某種程度上,LLM 的質量是不言而喻的)。但在去中心化的世界中,誠實不是假設的——而是經過驗證的。
這就是可驗證的推論發揮作用的地方。除了提供對查詢的響應之外,你還可以證明它在你要求的模型上正確運行。但如何呢?
最簡單的方法是將模型作爲鏈上智能合約運行。這肯定會保證輸出得到驗證,但這非常不切實際。GPT-3 表示嵌入維度爲 12,288 的單詞。如果你要在鏈上進行一次如此規模的矩陣乘法,按照當前的 Gas 價格計算,將花費約 100 億美元——計算將連續大約一個月填滿每個區塊。
所以不行。我們需要一種不同的方法。
在觀察了整個情況之後,我很清楚已經出現了三種主要方法來解決可驗證的推理:零知識證明、樂觀欺詐證明和加密經濟學。每個都有其自己的安全性和成本影響。
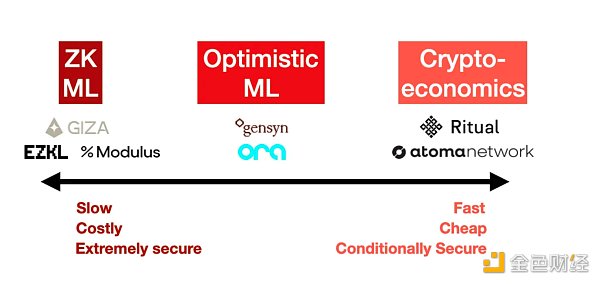
1.零知識證明(ZK ML)
想象一下,能夠證明你運行了一個大型模型,但無論模型有多大,證明實際上都是固定大小的。這就是 ZK ML 通過 ZK-SNARK 的魔力所承諾的。
雖然原則上聽起來很優雅,但將深度神經網絡編譯成零知識電路並進行證明是極其困難的。它的成本也非常高——至少,你可能會看到1000 倍的推理成本和 1000 倍的延遲(生成證明的時間),更不用說在這一切發生之前將模型本身編譯成電路了。最終,該成本必須轉嫁給用戶,因此對於最終用戶而言,這最終將非常昂貴。
另一方面,這是通過密碼學保證正確性的唯一方法。有了ZK,模型提供者無論多么努力都無法作弊。但這樣做的成本巨大,使得在可預見的未來對於大型模型來說這是不切實際的。
示例:EZKL、Modulus Labs、Giza
2.樂觀欺詐證明(Optimistic ML)
樂觀的方法是信任,但要驗證。除非另有證明,否則我們假設推論是正確的。如果一個節點試圖作弊,網絡中的“觀察者”可以指出作弊者並使用欺詐證明來挑战他們。這些觀察者必須始終觀察鏈並在自己的模型上重新運行推理,以確保輸出正確。
這些欺詐證明是Truebit 風格的交互式挑战-響應遊戲,你可以在鏈上反復平分模型執行軌跡,直到找到錯誤。
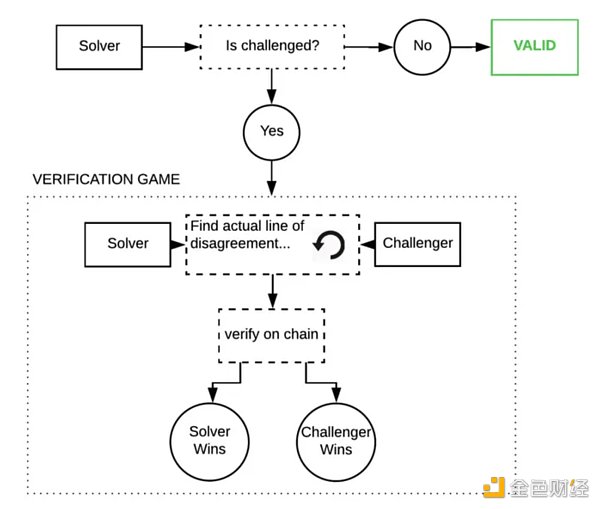
如果這種情況真的發生,其成本將非常高昂,因爲這些程序非常龐大並且具有巨大的內部狀態——單個 GPT-3 推理的成本約爲1 petaflop(10^5 浮點運算)。但博弈論表明這種情況幾乎永遠不會發生(衆所周知,欺詐證明很難正確編碼,因爲代碼幾乎永遠不會在生產中受到攻擊)。
樂觀的好處是,只要有一個誠實的觀察者在關注,機器學習就是安全的。成本比 ZK ML 便宜,但請記住,網絡中的每個觀察者都會自行重新運行每個查詢。在均衡狀態下,這意味着如果有 10 個觀察者,則安全成本必須轉嫁給用戶,因此他們將必須支付超過 10 倍的推理成本(或者無論觀察者有多少)。
與樂觀匯總一樣,缺點是你必須等待挑战期過去才能確定響應已得到驗證。不過,根據網絡參數化的方式,你可能需要等待幾分鐘而不是幾天。
示例:Ora、Gensyn(盡管目前未指定)
3.加密經濟學(加密經濟ML)
在這裏,我們放棄所有花哨的技術,做簡單的事情:股權加權投票。用戶決定應該有多少個節點運行他們的查詢,每個節點都會顯示他們的響應,如果響應之間存在差異,那么奇怪的節點就會被削減。標准的預言機東西——這是一種更直接的方法,可以讓用戶設置他們想要的安全級別,平衡成本和信任。如果 Chainlink 正在做機器學習,他們就會這樣做。
這裏的延遲很快——你只需要每個節點的提交-顯示。如果將其寫入區塊鏈,那么從技術上講,這可能會發生在兩個區塊中。
然而,安全性是最薄弱的。如果足夠狡猾,大多數節點可以理性地選擇共謀。作爲用戶,你必須推斷這些節點的風險有多大以及作弊將花費多少成本。也就是說,使用 Eigenlayer 重新抵押和可歸因安全之類的東西,網絡可以在安全失敗的情況下有效地提供保險。
但該系統的優點在於用戶可以指定他們想要的安全程度。他們可以選擇在仲裁中包含 3 個節點或 5 個節點,或者網絡中的每個節點 - 或者,如果他們想要 YOLO,他們甚至可以選擇 n=1。這裏的成本函數很簡單:用戶爲他們想要的法定數量的節點付費。如果選擇 3,則需要支付 3 倍的推理成本。
這裏有一個棘手的問題:你能讓 n=1 安全嗎?在一個簡單的實現中,如果沒有人檢查,一個單獨的節點應該每次都作弊。但我懷疑,如果你對查詢進行加密並通過意圖進行付款,你可能能夠向節點混淆它們實際上是唯一響應此任務的節點。在這種情況下,你可能可以向普通用戶收取不到 2 倍的推理成本。
最終,加密經濟方法是最簡單、最容易,也可能是最便宜的,但它是最不性感的,原則上也是最不安全的。但一如既往,細節決定成敗。
示例:Ritual(盡管目前未具體說明)、Atoma Network
爲什么可驗證的機器學習很難
你可能想知道爲什么我們還沒有擁有這一切?畢竟,從本質上來說,機器學習模型只是非常大型的計算機程序。長期以來,證明程序正確執行一直是區塊鏈的基礎。
這就是爲什么這三種驗證方法反映了區塊鏈保護其區塊空間的方式——ZK rollups 使用 ZK 證明,optimistic rollups 使用欺詐證明,而大多數 L1 區塊鏈使用加密經濟學。毫不奇怪,我們得出了基本相同的解決方案。那么,是什么讓這在應用於機器學習時變得困難呢?
ML 是獨一無二的,因爲 ML 計算通常表示爲密集計算圖,旨在在 GPU 上高效運行。它們並不是爲了被證明而設計的。因此,如果你想在 ZK 或樂觀環境中證明 ML 計算,則必須以使其成爲可能的格式重新編譯——這是非常復雜且昂貴的。
機器學習的第二個基本困難是不確定性。程序驗證假設程序的輸出是確定性的。但如果你在不同的 GPU 架構或 CUDA 版本上運行相同的模型,你將得到不同的輸出。即使你必須強制每個節點使用相同的架構,你仍然會遇到算法中使用的隨機性問題(擴散模型中的噪聲,或 LLM 中的令牌採樣)。你可以通過控制RNG種子來修復隨機性。但即便如此,你仍然面臨最後一個威脅性問題:浮點運算固有的不確定性。
GPU 中的幾乎所有運算都是在浮點數上完成的。浮點很挑剔,因爲它們不具有關聯性——也就是說,對於浮點來說 (a + b) + c 並不總是與 a + (b + c) 相同。由於 GPU 是高度並行化的,因此每次執行時加法或乘法的順序可能會有所不同,這可能會導致輸出出現微小差異。考慮到單詞的離散性質,這不太可能影響 LLM 的輸出,但對於圖像模型來說,它可能會導致像素值略有不同,從而導致兩個圖像無法完美匹配。
這意味着你要么需要避免使用浮點,這意味着對性能的巨大打擊,要么你需要在比較輸出時允許一些寬松。無論哪種方式,細節都是復雜的,你無法完全將它們抽象出來。(事實證明,這就是爲什么 EVM不支持浮點數,盡管NEAR等一些區塊鏈支持浮點數。)
簡而言之,去中心化推理網絡很難,因爲所有細節都很重要,而現實的細節數量驚人。
結語
目前,區塊鏈和機器學習顯然有很多共同之處。一種是創造信任的技術,另一種是迫切需要信任的技術。雖然每種去中心化推理方法都有其自身的權衡,但我非常有興趣了解企業家如何使用這些工具來構建最好的網絡。
 打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 金色精選 > Dragonfly Capital 合夥人:去中心化推理的信任問題與驗證挑战
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 金色精選 > Dragonfly Capital 合夥人:去中心化推理的信任問題與驗證挑战
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
標題:Dragonfly Capital 合夥人:去中心化推理的信任問題與驗證挑战
地址:https://www.coinsdeep.com/article/108731.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。