ChatGPT勾起AI狂熱:區塊鏈「去中心算力」如何解決機器學習的瓶頸?
發表於 2023-04-07 20:00 作者: 區塊鏈情報速遞pro
人工智能發展看似進展順利,但仍有一些潛在的挑戰和瓶頸需要解決,去中心化解決方案也許能加速AI發展。本文源自研究機構Messari分析師Sami Kassab所著《Decentralizing Machine Learning》,由BlockTurbo編譯、星球日報整理。 (前情提要:ChatGPT-5年底推出!OpenAI放話:智慧遠超人類,可能對世界帶來巨大風險 ) (背景補充:AI封殺潮》ChatGPT遭德法、瑞典..調查,VPN翻牆成必備工具? )
過去兩周,生成式人工智慧 (AI) 領域是毫無疑問的熱點,突破性的新版本和尖端集成不斷湧現。 OpenAI 發布了備受期待的 GPT-4 模型,Midjourney 發布了最新的 V 5 模型,Stanford 發布了 Alpaca 7 B 語言模型。與此同時,谷歌在其整個 Workspace 套件中推出了生成式人工智慧,Anthropic 推出了其人工智慧助手 Claude,而微軟則將其強大的生成式人工智慧工具 Copilot 集成到了 Microsoft 365 套件中。
隨著企業開始意識到人工智慧和自動化的價值以及採用這些技術以保持市場競爭力的必要性,人工智慧開發和採用的步伐愈發加快。
儘管人工智慧發展看似進展順利,但仍有一些潛在的挑戰和瓶頸需要解決。隨著越來越多的企業和消費者接受人工智慧,計算能力方面的瓶頸正在出現。人工智慧系統所需的計算量每隔幾個月就會翻一番,而計算資源的供應卻難以跟上步伐。此外,訓練大規模人工智慧模型的成本持續飆升,過去十年每年增長約 3100% 。
開發和訓練尖端人工智慧系統所需的成本上升和資源需求增加的趨勢正在導致集中化,只有擁有大量預算的實體才能進行研究和生產模型。然而,一些基於加密技術的項目正在構建去中心化解決方案,以使用開放計算和機器智能網路解決這些問題。
人工智慧(AI)和機器學習(ML)基礎
AI 領域可能令人望而生畏,深度學習、神經網路和基礎模型等技術術語增加了其覆雜性。現在,就讓我們簡化這些概念以便於理解。
- 人工智慧是電腦科學的一個分支,涉及開發算法和模型,使電腦能夠執行需要人類智能的任務,例如感知、推理和決策制定;
- 機器學習 (ML) 是 AI 的一個子集,它涉及訓練算法以識別數據中的模式並根據這些模式進行預測;
- 深度學習是一種涉及使用神經網路的 ML,神經網路由多層相互連接的節點組成,這些節點協同工作以分析輸入數據並生成輸出。
基礎模型,例如 ChatGPT 和 Dall-E,是經過大量數據預訓練的大規模深度學習模型。這些模型能夠學習數據中的模式和關係,使它們能夠生成與原始輸入數據相似的新內容。 ChatGPT 是一種用於生成自然語言文本的語言模型,而 Dall-E 是一種用於生成新穎圖像的圖像模型。
AI 和 ML 行業的問題
人工智慧的進步主要由三個因素驅動:
- 算法創新:研究人員不斷開發新的算法和技術,讓人工智慧模型能夠更高效、更準確地處理和分析數據。
- 數據:人工智慧模型依賴大型數據集作為訓練的燃料,使它們能夠從數據中的模式和關係中學習。
- 計算:訓練 AI 模型所需的覆雜計算需要大量的計算處理能力。
然而,有兩個主要問題阻礙了人工智慧的發展。回到 2021 年,獲取數據是人工智慧企業在人工智慧發展過程中面臨的首要挑戰。去年,與計算相關的問題超越了數據成為挑戰,特別是由於高需求驅動下無法按需訪問計算資源。
第二個問題與算法創新效率低下有關。雖然研究人員通過在以前的模型的基礎上繼續對模型進行增量改進,但這些模型提取的智能或模式總是會丟失。
讓我們更深入地研究這些問題。
計算瓶頸
訓練基礎機器學習模型需要大量資源,通常需要長時間使用大量 GPU。例如,Stability.AI 需要在 AWS 的雲中運行 4, 000 個 Nvidia A 100 GPU 來訓練他們的 AI 模型,一個月花費超過 5000 萬美元。另一方面,OpenAI 的 GPT-3 使用 1, 000 個 Nvidia V1 00 GPU 進行訓練,耗資 1, 200 萬美元。
人工智慧公司通常面臨兩種選擇:投資自己的硬體並犧牲可擴展性,或者選擇雲端服務商並支付高價。雖然大公司有能力選擇後者,但小公司可能沒有那麼奢侈。隨著資本成本的上升,初創公司被迫削減雲支出,即使大型雲提供商擴展基礎設施的成本基本保持不變。
人工智慧的高昂計算成本給追求該領域進步的研究人員和組織造成了重大障礙。目前,迫切需要一種經濟實惠的服務器計算平台來進行 ML 工作,這在傳統電腦領域是不存在的。幸運的是,一些加密項目正在致力於開發可以滿足這一需求的去中心化機器學習計算網路。
效率低下和缺乏協作
越來越多的人工智慧開發是在大型科技公司祕密進行的,而不是在學術界。這種趨勢導致該領域內的合作減少,例如微軟的 OpenAI 和谷歌的 DeepMind 等公司相互競爭並保持其模型的私密性。
缺乏協作導致效率低下。例如,如果一個獨立的研究團隊想要開發一個更強大的 OpenAI 的 GPT-4 版本,他們將需要從頭開始重新訓練模型,基本上是重新學習 GPT-4 訓練的所有內容。考慮到僅 GPT-3 的培訓成本就高達 1200 萬美元,這讓規模較小的 ML 研究實驗室處於劣勢,並將人工智慧發展的未來進一步推向大型科技公司的控制。
但是,如果研究人員可以在現有模型的基礎上構建而不是從頭開始,從而降低進入壁壘;如果有一個激勵合作的開放網路,作為一個自由市場管理的模型協調層,研究人員可以在其中使用其他模型訓練他們的模型,會怎麼樣呢?去中心化機器智能項目 Bittensor 就構建了這種類型的網路。
機器學習的分散式計算網路
去中心化計算網路通過激勵 CPU 和 GPU 資源對網路的貢獻,將尋求計算資源的實體連接到具有閒置計算能力的系統。由於個人或組織提供其閒置資源沒有額外成本,因此與中心化提供商相比,去中心化網路可以提供更低的價格。
存在兩種主要類型的分散式計算網路:通用型和專用型。通用計算網路像分散式雲一樣運行,為各種應用程式提供計算資源。另一方面,特定用途的計算網路是針對特定用例量身定制的。例如,渲染網路是一個專注於渲染工作負載的專用計算網路。
盡管大多數 ML 計算工作負載可以在分散的雲上運行,但有些更適合特定用途的計算網路,如下所述。
機器學習計算工作負載
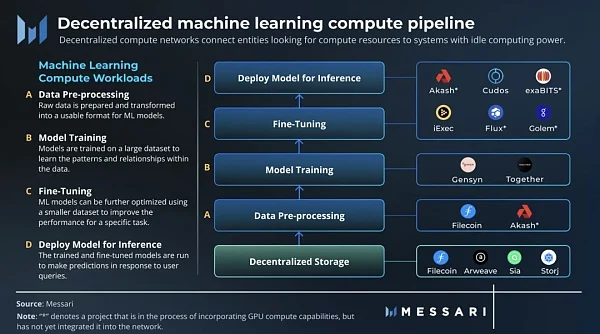
機器學習可以分為四種主要的計算工作負載:
- 數據預處理:準備原始數據並將其轉換為 ML 模型可用的格式,這通常涉及數據清理和規範化等活動。
- 訓練:機器學習模型在大型數據集上進行訓練,以學習數據中的模式和關係。在訓練期間,調整模型的參數和權重以最小化誤差。
- 微調:可以使用較小的數據集進一步優化 ML 模型,以提高特定任務的性能。
- 推理:運行經過訓練和微調的模型以響應用戶查詢進行預測。
數據預處理、微調和推理工作負載非常適合在 Akash、Cudos 或 iExec 等去中心化雲平台上運行。然而,去中心化儲存網路 Filecoin 由於其最近的升級而特別適合數據預處理,從而啟用了 Filecoin 虛擬機(FVM)。 FVM 升級可以對儲存在網路上的數據進行計算,為已經使用它進行數據儲存的實體提供更高效的解決方案。
機器學習專用計算網路
由於圍繞並行化和驗證的兩個挑戰,訓練部分需要一個特定用途的計算網路。
ML 模型的訓練依賴於狀態,這意味著計算的結果取決於計算的當前狀態,這使得利用分布式 GPU 網路變得更加覆雜。因此,需要一個專為 ML 模型並行訓練而設計的特定網路。
更重要的問題與驗證有關。要構建信任最小化的 ML 模型訓練網路,網路必須有一種方法來驗證計算工作,而無需重覆整個計算,否則會浪費時間和資源。
Gensyn
Gensyn 是一種特定於 ML 的計算網路,它已經找到了以分散和分布式方式訓練模型的並行化和驗證問題的解決方案。該協議使用並行化將較大的計算工作負載拆分為任務,並將它們異步推送到網路。為了解決驗證問題,Gensyn 使用概率學習證明、基於圖形的精確定位協議以及基於抵押和削減的激勵系統。
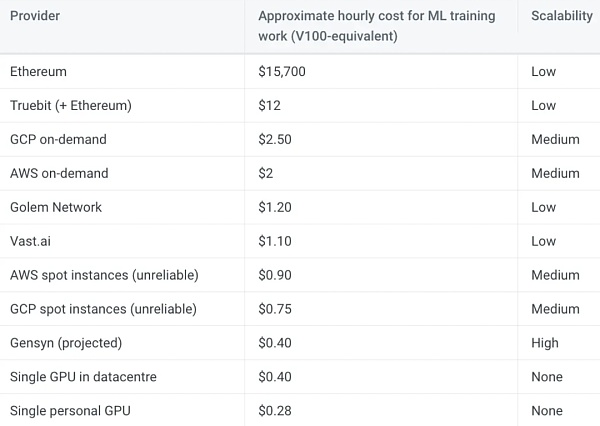
盡管 Gensyn 網路尚未上線,但該團隊預測其網路上 V1 00 等效 GPU 的每小時成本約為 0.40 美元。這一估計是基於以太坊礦工在 Merge 之前使用類似 GPU 每小時賺取 0.20 至 0.35 美元。即使這個估計有 100% 的偏差,Gensyn 的計算成本仍將大大低於 AWS 和 GCP 提供的按需服務。
Together
Together 是另一個專注於構建專門用於機器學習的去中心化計算網路的早期項目。在項目啟動之初,Together 開始整合來自斯坦福大學、蘇黎世聯邦理工學院、Open Science Grid、威斯康星大學麥迪遜分校和 CrusoeCloud 等不同機構未使用的學術計算資源,從而產生總計超過 200 PetaFLOP 的計算能力。他們的最終目標是通過匯集全球計算資源,創造一個任何人都可以為先進人工智慧做出貢獻並從中受益的世界。
Bittensor:去中心化機器智能
Bittensor 解決了機器學習中的低效率問題,同時通過使用標準化的輸入和輸出編碼來激勵開源網路上的知識生產,從而改變研究人員的協作方式,以實現模型互操作性。
在 Bittensor 上,礦工因通過獨特的 ML 模型為網路提供智能服務而獲得網路的本地資產 TAO 的獎勵。在網路上訓練他們的模型時,礦工與其他礦工交換信息,加速他們的學習。通過抵押 TAO,用戶可以使用整個 Bittensor 網路的智能並根據他們的需要調整其活動,從而形成 P2P 智能市場。此外,應用程式可以通過網路的驗證器構建在網路的智能層之上。
Bittensor 是如何工作的
Bittensor 是一種開源 P2P 協議,它實現了分散的專家混合 (MoE),這是一種 ML 技術,結合了專門針對不同問題的多個模型,以創建更準確的整體模型。這是通過訓練稱為門控層的路由模型來完成的,該模型在一組專家模型上進行訓練,以學習如何智能地路由輸入以產生最佳輸出。為實現這一目標,驗證器動態地在相互補充的模型之間形成聯盟。稀疏計算用於解決延遲瓶頸。
Bittensor 的激勵機制吸引了專門的模型加入混合體,並在解決利益相關者定義的更大問題中發揮利基作用。每個礦工代表一個獨特的模型(神經網路),Bittensor 作為模型的自我協調模型運行,由未經許可的智能市場系統管理。
該協議與算法無關,驗證者只定義鎖並允許市場找到密鑰。礦工的智能是唯一共享和衡量的組成部分,而模型本身仍然是私有的,從而消除了衡量中的任何潛在偏見。
驗證者
在 Bittensor 上,驗證器充當網路 MoE 模型的門控層,充當可訓練的 API 並支持在網路之上開發應用程式。他們的質押支配著激勵格局,並決定了礦工要解決的問題。驗證者了解礦工提供的價值,以便相應地獎勵他們並就他們的排名達成共識。排名較高的礦工獲得更高份額的通貨膨脹區塊獎勵。
驗證者也被激勵去誠實有效地發現和評估模型,因為他們獲得了他們排名靠前的礦工的債券,並獲得了他們未來獎勵的一部分。這有效地創造了一種機制,礦工在經濟上將自己「綁定」到他們的礦工排名。該協議的共識機制旨在抵制高達 50% 的網路股份的串通,這使得不誠實地對自己的礦工進行高度排名在財務上是不可行的。
礦工
網路上的礦工接受訓練和推理,他們根據自己的專業知識有選擇地與同行交換信息,並相應地更新模型的權重。在交換信息時,礦工根據他們的股份優先處理驗證者請求。目前有 3523 名礦工在線。
礦工之間在 Bittensor 網路上的信息交換允許創建更強大的 AI 模型,因為礦工可以利用同行的專業知識來改進他們自己的模型。這實質上為 AI 空間帶來了可組合性,不同的 ML 模型可以在其中連接以創建更覆雜的 AI 系統。
複合智能
Bittensor 通過新市場解決激勵低效問題,從而有效地實現機器智能的覆合,從而提高 ML 培訓的效率。該網路使個人能夠為基礎模型做出貢獻並將他們的工作貨幣化,無論他們貢獻的規模或利基如何。這類似於網際網路如何使利基貢獻在經濟上可行,並在 YouTube 等內容平台上賦予個人權力。本質上,Bittensor 致力於將機器智能商品化,成為人工智慧的網際網路。
總結
隨著去中心化機器學習生態系統的成熟,各種計算和智能網路之間很可能會產生協同效應。例如 Gensyn 和 Together 可以作為 AI 生態的硬體協調層,而 Bittensor 可以作為智能協調層。
在供應方面,以前開採 ETH 的大型公共加密礦工對為去中心化計算網路貢獻資源表現出極大的興趣。例如,在他們的網路 GPU 發布之前,Akash 已經從大型礦工那裡獲得了 100 萬個 GPU 的承諾。此外,較大的私人比特幣礦工之一的 Foundry 已經在 Bittensor 上進行挖礦。
本報告中討論的項目背後的團隊不僅僅是為了炒作而構建基於加密技術的網路,而是 AI 研究人員和工程師團隊,他們已經意識到加密在解決其行業問題方面的潛力。
通過提高訓練效率、實現資源池化並為更多人提供為大規模 AI 模型做出貢獻的機會,去中心化 ML 網路可以加速 AI 發展,讓我們在未來更快解鎖通用人工智慧。

?相關報導?
ChatGPT-5年底推出!OpenAI放話:智慧遠超人類,可能對世界帶來巨大風險
AI封殺潮》ChatGPT遭德法、瑞典..調查,VPN翻牆成必備工具?
義大利開首槍!因隱私疑慮暫時封禁ChatGPT,OpenAI:已在該國下線
Tags: AIBittensorChatGPTGensynOpenAITOGETHER人工智慧人工智能去中心化算力機器學習礦工算力顯卡標題:ChatGPT勾起AI狂熱:區塊鏈「去中心算力」如何解決機器學習的瓶頸?
地址:https://www.coinsdeep.com/article/12107.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。