谷歌反擊:Project Astra正面硬剛GPT-4o Veo對抗Sora
發表於 2024-05-15 08:44 作者: 機器之能
來源:機器之心
機器之心編輯部
通用的 AI,能夠真正日常用的 AI,不做成這樣現在都不好意思开發布會了。
5 月 15 日凌晨,一年一度的「科技界春晚」Google I/O 开發者大會正式开幕。長達 110 分鐘的主 Keynote 提到了幾次人工智能?谷歌自己統計了一下:

是的,每一分鐘都在講 AI。
生成式 AI 的競爭,最近又達到了新的高潮,本次 I/O 大會的內容自然全面圍繞人工智能展开。
「一年前在這個舞台上,我們首次分享了原生多模態大模型 Gemini 的計劃。它標志着新一代的 I/O,」谷歌首席執行官桑達爾・皮查伊(Sundar Pichai)說道。「今天,我們希望每個人都能從 Gemini 的技術中受益。這些突破性的功能將進入搜索、圖片、生產力工具、安卓系統等方方面面。」
24 小時以前,OpenAI 故意搶先發布 GPT-4o,通過實時的語音、視頻和文本交互震撼了全世界。今天,谷歌展示的 Project Astra 和 Veo,直接對標了目前 OpenAI 領先的 GPT-4o 與 Sora。
這是 Project Astra 原型的實時拍攝:
我們正在見證最高端的商战,以最樸實的方式進行着。
最新版 Gemini 革新谷歌生態
在 I/O 大會上,谷歌展示了最新版 Gemini 加持的搜索能力。
25 年前,谷歌通過搜索引擎推動了第一波信息時代的浪潮。現在,隨着生成式 AI 技術的演進,搜索引擎可以更好地幫你回答問題,它可以更好地利用上下文內容、位置感知和實時信息能力。
基於最新版本的定制化 Gemini 大模型,你可以對搜索引擎提出任何你想到的事情,或任何需要完成的事 —— 從研究到計劃到想象,谷歌將負責所有工作。
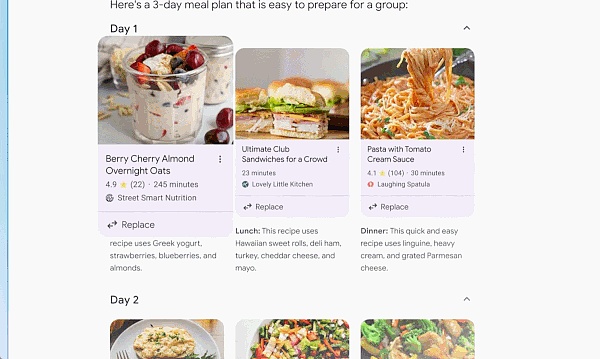
有時你想要快速得到答案,但沒有時間將所有信息拼湊在一起。這個時候,搜索引擎將通過 AI 概述爲你完成工作。通過人工智能概述,AI 可以自動訪問大量網站來提供一個復雜問題的答案。
借助定制 Gemini 的多步推理功能,AI 概述將有助於解決日益復雜的問題。你無需再將問題分解爲多個搜索,現在可以一次性提出最復雜的問題,以及你想到的所有細微差別和注意事項。
除了爲復雜問題找到正確的答案或信息之外,搜索引擎還可以與你一起,一步步制定計劃。
在 I/O 大會上,谷歌重點強調了大模型的多模態和長文本能力。技術的進步爲 Google Workspace 等生產力工具變得更加智能化。
例如,現在我們可以要求 Gemini 總結一下學校最近發來的所有電子郵件。它會在後台識別相關的 Email,甚至分析 PDF 等附件。隨後你就能獲得其中的要點和行動項目的摘要。

如果你正在旅行,無法參加項目會議,而會議的錄音長達一個小時。如果是 Google Meet 上开的會,你可以要求 Gemini 給你介紹一下重點。有一個小組在尋找志愿者,那天你有空。Gemini 可以幫你寫一封郵件進行申請。
更進一步,谷歌在大模型 Agent 上看到了更多的機會,認爲它們可作爲具有推理、計劃和記憶能力的智能系統。利用 Agent 的應用能夠提前「思考」多個步驟,並跨軟件和系統工作,更加便捷地幫你完成任務。這種思路已經在搜索引擎等產品中得到了體現,人們都可以直接看到 AI 能力的提升。
至少在全家桶應用方面,谷歌是領先於 OpenAI 的。
Gemini 家族大更新
Project Astra 上线
生態上谷歌有先天優勢,但大模型基礎很重要,谷歌爲此整合了自身團隊和 DeepMind 的力量。今天哈薩比斯也首次在 I/O 大會上登台,親自介紹了神祕的新模型。

去年 12 月,谷歌推出了首款原生多模態模型 Gemini 1.0,共有三種尺寸:Ultra、Pro 和 Nano。僅僅幾個月後,谷歌發布新版本 1.5 Pro,其性能得到了增強,並且上下文窗口突破了 100 萬 token。
現在,谷歌宣布在 Gemini 系列模型中引入了一系列更新,包括新的 Gemini 1.5 Flash(這是谷歌追求速度和效率的輕量級模型)以及 Project Astra(這是谷歌對人工智能助手未來的愿景)。
目前,1.5 Pro 和 1.5 Flash 均已提供公共預覽版,並在 Google AI Studio 和 Vertex AI 中提供 100 萬 token 上下文窗口。現在,1.5 Pro 還通過候補名單向使用 API 的开發人員和 Google Cloud 客戶提供了 200 萬 token 上下文窗口。
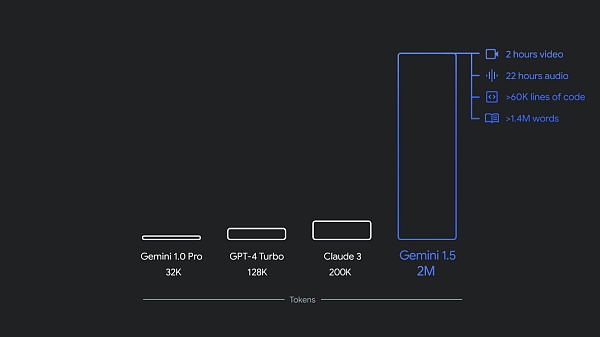
此外,Gemini Nano 也從純文本輸入擴展到可以圖片輸入。今年晚些時候,從 Pixel 开始,谷歌將推出多模態 Gemini Nano 。這意味着手機用戶不僅能夠處理文本輸入,還能夠理解更多上下文信息,例如視覺、聲音和口語。
Gemini 家族迎來新成員:Gemini 1.5 Flash
新的 1.5 Flash 針對速度和效率進行了優化。
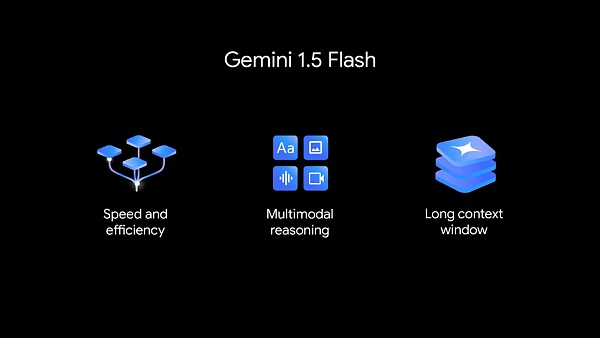
1.5 Flash 是 Gemini 模型系列的最新成員,也是 API 中速度最快的 Gemini 模型。它針對大規模、大批量、高頻任務進行了優化,服務更具成本效益,並具有突破性的長上下文窗口(100 萬 token )。

Gemini 1.5 Flash 具有很強的多模態推理能力,並具有突破性的長上下文窗口。
1.5 Flash 擅長摘要、聊天應用程序、圖像和視頻字幕、從長文檔和表格中提取數據等。這是因爲 1.5 Pro 通過一個名爲「蒸餾」的過程對其進行了訓練,將較大模型中最基本的知識和技能遷移到較小、更高效的模型中。
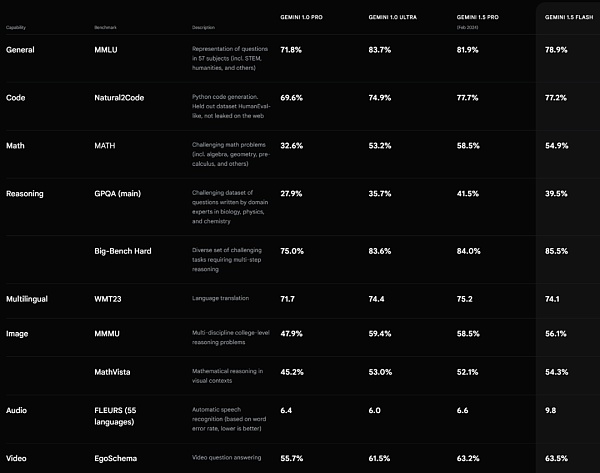
Gemini 1.5 Flash 性能表現。來源 https://deepmind.google/technologies/gemini/#introduction
改進的 Gemini 1.5 Pro 上下文窗口擴展到 200 萬 token
谷歌提到,如今有超過 150 萬的开發人員在使用 Gemini 模型,超過 20 億的產品用戶都用到了 Gemini。

在過去的幾個月裏,谷歌除了將 Gemini 1.5 Pro 上下文窗口擴展到 200 萬 token 之外,谷歌還通過數據和算法的改進增強了其代碼生成、邏輯推理和規劃、多輪對話以及音頻和圖像理解能力。

1.5 Pro 現在可以遵循日益復雜和細致的指令,包括那些指定涉及角色,格式和風格的產品級行爲的指令。此外,谷歌還讓用戶能夠通過設置系統指令來引導模型行爲。
現在,谷歌在 Gemini API 和 Google AI Studio 中添加了音頻理解,因此 1.5 Pro 現在可以對 Google AI Studio 中上傳的視頻圖像和音頻進行推理。此外,谷歌還將 1.5 Pro 集成到 Google 產品中,包括 Gemini Advanced 和 Workspace 應用程序。
Gemini 1.5 Pro 的定價爲每 100 萬 token 3.5 美元。
其實,Gemini 最令人興奮的轉變之一是 Google 搜索。
在過去的一年裏,作爲搜索生成體驗的一部分,Google 搜索回答了數十億個查詢。現在,人們可以使用它以全新的方式進行搜索,提出新類型的問題、更長、更復雜的查詢,甚至使用照片進行搜索,並獲得網絡所提供的最佳信息。
谷歌即將推出 Ask Photos 功能。以 Google Photos 舉例,該功能大約在九年前推出。如今,用戶每天上傳的照片和視頻數量超過 60 億張。人們喜歡使用照片來搜索他們的生活。Gemini 讓這一切變得更加容易。
假設你正在停車場付款,但不記得自己的車牌號碼。之前,你可以在照片中搜索關鍵字,然後滾動瀏覽多年的照片,尋找車牌。現在,你只需詢問照片即可。

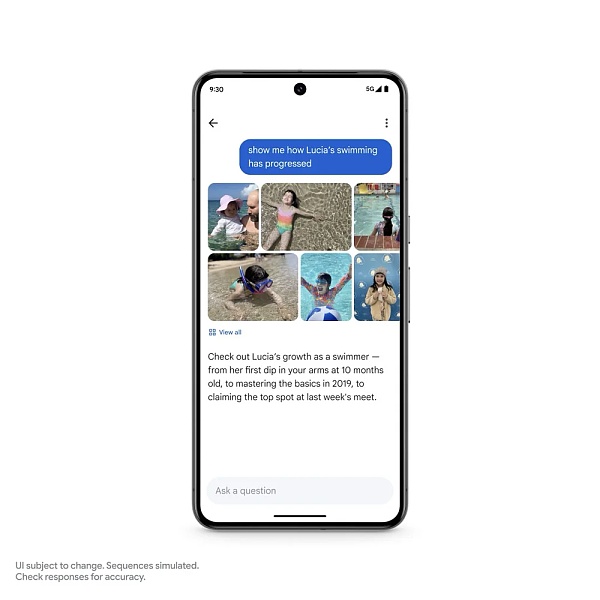
又比如,你回憶女兒露西婭的早期生活。現在,你可以問照片:露西亞什么時候學會遊泳的?你還可以跟進一些更復雜的事情:告訴我露西婭的遊泳進展如何。
在這裏,Gemini 超越了簡單的搜索,識別了不同的背景 —— 包括遊泳池、大海等不同場景,照片將所有內容匯總在一起,以便用戶查看。谷歌將於今年夏天推出 Ask Photos 功能,並且還將推出更多功能。

新一代开源大模型 Gemma 2
今天,谷歌還發布了开源大模型 Gemma 的一系列更新 ——Gemma 2 來了。
據介紹,Gemma 2 採用全新架構,旨在實現突破性的性能和效率,新开源的模型參數爲 27B。

此外,Gemma 家族也在隨着 PaliGemma 的擴展而擴展,PaliGemma 是谷歌受 PaLI-3 啓發的第一個視覺語言模型。
通用 AI 智能體 Project Astra
一直以來,智能體都是 Google DeepMind 的重點研究方向。
昨天,我們圍觀了 OpenAI 的 GPT-4o,爲其強大的實時語音、視頻交互能力所震撼。
今天,DeepMind 的視覺與語音交互通用 AI 智能體項目 Project Astra 亮相,這是 Google DeepMind 對未來 AI 助手的一個展望。
谷歌表示,爲了真正發揮作用,智能體需要像人類一樣理解和響應復雜、動態的真實世界,也需要吸收並記住所看到和聽到的內容,以了解上下文並採取行動。此外,智能體還需要具有主動性、可教育和個性化,以便用戶可以自然地與它交談,沒有滯後或延遲。
在過去的幾年裏,谷歌一直致力於改進模型的感知、推理和對話方式,以使交互的速度和質量更加自然。
在今天的 Keynote 中, Google DeepMind 展示了 Project Astra 的交互能力:
據介紹,谷歌是在 Gemini 的基礎上开發了智能體原型,它可以通過連續編碼視頻幀、將視頻和語音輸入組合到事件時間线中並緩存此信息以進行有效調用,從而更快地處理信息。
通過語音模型,谷歌還強化了智能體的發音,爲智能體提供了更廣泛的語調。這些智能體可以更好地理解他們所使用的上下文,並在對話中快速做出響應。
這裏簡單評論一下。機器之心感覺 Project Astra 項目發布的 Demo,在交互體驗上要比 GPT-4o 實時演示的能力要差許多。無論是響應的時長、語音的情感豐富度、可打斷等方面,GPT-4o 的交互體驗似乎更自然。不知道讀者們感覺如何?
反擊 Sora:發布視頻生成模型 Veo
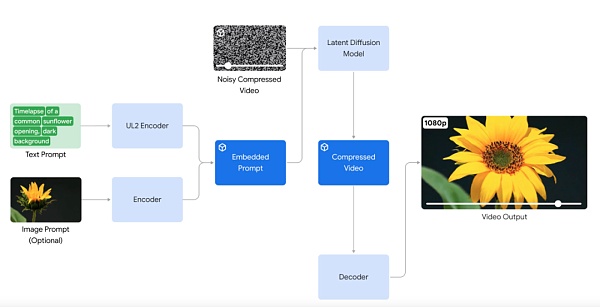
在 AI 生成視頻方面,谷歌宣布推出視頻生成模型 Veo。Veo 能夠生成各種風格的高質量 1080p 分辨率視頻,時長可以超過一分鐘。
憑借對自然語言和視覺語義的深入理解,Veo 模型在理解視頻內容、渲染高清圖像、模擬物理原理等方面都有所突破。Veo 生成的視頻能夠准確、細致地表達用戶的創作意圖。
例如,輸入文本 prompt:
Many spotted jellyfish pulsating under water. Their bodies are transparent and glowing in deep ocean.
(許多斑點水母在水下搏動。它們的身體透明,在深海中閃閃發光。)
再比如生成人物視頻,輸入 prompt:
A lone cowboy rides his horse across an open plain at beautiful sunset, soft light, warm colors.
(在美麗的日落、柔和的光线、溫暖的色彩下,一個孤獨的牛仔騎着馬穿過开闊的平原。)
近景人物視頻,輸入 prompt:
A woman sitting alone in a dimly lit cafe, a half-finished novel open in front of her. Film noir aesthetic, mysterious atmosphere. Black and white.
(一個女人獨自坐在燈光昏暗的咖啡館裏,一本未完成的小說攤在她面前。黑色電影唯美,神祕氣氛。黑白。)
值得注意的是,Veo 模型提供了前所未有的創意控制水平,並理解「延時拍攝」、「航拍」等電影術語,使視頻連貫、逼真。
例如電影級海岸线航拍鏡頭,輸入 prompt:
Drone shot along the Hawaii jungle coastline, sunny day
(無人機沿夏威夷叢林海岸线拍攝,陽光明媚的日子)
Veo 還支持以圖像和文本一起作爲 prompt,來生成視頻。通過提供參考圖像與文本提示,Veo 生成的視頻會遵循圖像風格和用戶文本說明。
有趣的是,谷歌發布的 demo 是 Veo 生成的「羊駝」視頻,很容易讓人聯想到 Meta 的开源系列模型 Llama。

在長視頻方面,Veo 能夠制作 60 秒甚至更長的視頻。它可以通過單個 prompt 來完成此操作,也可以通過提供一系列 prompt 來完成此操作,這些 prompt 一起講述一個故事。這一點對視頻生成模型應用於影視制作非常關鍵。
Veo 以谷歌的視覺內容生成工作爲基礎,包括生成式查詢網絡 (GQN)、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet、Lumiere 等。
從今天开始,谷歌會爲一些創作者在 VideoFX 中提供預覽版 Veo,創作者可以加入谷歌的 waitlist。谷歌還將把 Veo 的一些功能引入 YouTube Shorts 等產品。
文生圖新模型 Imagen 3
在文本到圖像生成方面,谷歌再次升級了系列模型 —— 發布 Imagen 3。
Imagen 3 在生成細節、光照、幹擾等方面進行了優化升級,並且理解 prompt 的能力顯著增強。
爲了幫助 Imagen 3 從較長的 prompt 中捕捉細節,例如特定的攝像機角度或構圖,谷歌在訓練數據中每個圖像的標題中添加了更豐富的細節。
例如,在輸入 prompt 中添加「在前景中略微虛焦」、「溫暖光线」等,Imagen 3 就可以按照要求生成圖像:

此外,谷歌特別針對圖像生成中「文字模糊」的問題進行了改進,即優化了圖像渲染,使生成圖像中文字清晰並風格化。

爲了提高可用性,Imagen 3 將提供多個版本,每個版本都針對不同類型的任務進行了優化。
從今天开始,谷歌爲一些創作者在 ImageFX 中提供 Imagen 3 預覽版,用戶可以注冊加入 waitlist。
第六代 TPU 芯片 Trillium
生成式 AI 正在改變人類與技術交互的方式,同時爲企業帶來巨大的增效機會。但這些進步需要更多的計算、內存和通信能力,以訓練和微調功能最強大的模型。
爲此,谷歌推出第六代 TPU Trillium,這是迄今爲止性能最強大、能效最高的 TPU,將於 2024 年底正式上市。
TPU Trillium 是一種高度定制化的 AI 專用硬件,此次 Google I/O 大會上宣布的多項創新,包括 Gemini 1.5 Flash、Imagen 3 和 Gemma 2 等新模型,均在 TPU 上進行訓練並使用 TPU 提供服務。

據介紹,與 TPU v5e 相比,Trillium TPU 的每芯片峰值計算性能提高了 4.7 倍,同時它還把高帶寬內存(HBM)以及芯片間互連(ICI)帶寬加倍。此外,Trillium 配備了第三代 SparseCore,專門用於處理高級排名和推薦工作負載中常見的超大型嵌入。
谷歌表示,Trillium 能夠以更快的速度訓練新一代 AI 模型,同時減少延遲和降低成本。此外,Trillium 還被稱爲迄今爲止谷歌最具可持續性的 TPU,與其前代產品相比,能效提高了超過 67%。
Trillium 可以在單個高帶寬、低延遲的計算集群(pod)中擴展到多達 256 個 TPU(張量處理單元)。除了這種集群級別的擴展能力之外,通過多片技術(multislice technology)和智能處理單元(Titanium Intelligence Processing Units,IPUs),Trillium TPU 可以擴展到數百個集群,連接成千上萬的芯片,形成一個由每秒數 PB(multi-petabit-per-second)數據中心網絡互聯的超級計算機。
谷歌早在 2013 年就推出了首款 TPU v1,隨後在 2017 年推出了雲 TPU,這些 TPU 一直在爲實時語音搜索、照片對象識別、語言翻譯等各種服務提供支持,甚至爲自動駕駛汽車公司 Nuro 等產品提供技術動力。
Trillium 也是谷歌 AI Hypercomputer 的一部分,這是一種开創性的超級計算架構,專爲處理尖端的 AI 工作負載而設計。谷歌正在與 Hugging Face 合作,優化开源模型訓練和服務的硬件。

以上,就是今天谷歌 I/O 大會的所有重點內容了。可以看出,谷歌在大模型技術與產品方面與 OpenAI 展开了全面競爭的態勢。而通過這兩天 OpenAI 與谷歌的發布,我們也能發現大模型競爭進入了到了一個新的階段:多模態、更自然地交互體驗成爲了大模型技術產品化並爲更多人所接受的關鍵。
期待 2024 年,大模型技術與產品創新,能爲我們帶來更多的驚喜。
標題:谷歌反擊:Project Astra正面硬剛GPT-4o Veo對抗Sora
地址:https://www.coinsdeep.com/article/123989.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。