智源大會2023觀後感:對AI更有信心 也更擔心人類了
發表於 2023-06-12 14:35 作者: 張無常
6月9日,爲期兩天的「北京智源大會」在中關村國家自主創新示範區會議中心成功开幕。
智源大會是智源研究院(也被稱爲中國OpenAI的最強中國AI研究院)主辦的年度國際性人工智能高端專業交流活動,定位於「AI內行頂級盛會」,也被戲稱爲「AI春晚」——從參會嘉賓陣容可見一斑:
圖靈獎得主Geoffrey Hinton、Yann LeCun(這也是深度學習三巨頭之二,另一位Bengio出席過之前的大會)、Joseph Sifakis和姚期智,張鈸、鄭南寧、謝曉亮、張宏江、張亞勤等院士,加州大學伯克利分校人工智能系統中心創始人Stuart Russell,麻省理工學院未來生命研究所創始人Max Tegmark,OpenAI首席執行官Sam Altman(這也是他的第一次中國演講,雖然是线上)、Meta、微軟、谷歌等大廠和DeepMind、Anthropic、HuggingFace、Midjourney、Stability AI等明星團隊成員,總共200余位人工智能頂尖專家……


這兩天跟着追完了大會直播,作爲一個不懂技術的文科生,竟然聽得津津有味,收獲滿滿。
不過,看完最後圖靈獎得主、「深度學習之父」Geoffrey Hinton 的演講,一種強烈而復雜的情緒籠罩了我:
一方面,看到AI研究者們對各類前沿技術的探索和暢想,會自然而然地對AI乃至未來的通用人工智能AGI的實現更有信心了;
另一方面,聽到最前沿的專家學者們討論AI的風險、以及人類對如何應對風險的無知和輕視,又對人類的未來充滿擔心——最本質的問題,用Hinton的話來說就是:歷史上從來沒有過更智能的事物被不那么智能的事物控制的先例,假如青蛙發明了人類,你覺得誰會取得控制權?是青蛙,還是人?
由於兩天的大會信息量爆炸,花點時間整理了一些重要演講的資料,順便記錄下自己的一些感想,方便後續復習查閱,也分享給關心AI進展的各位。
說明:下文標【注】部分爲個人感想,內容概括爲引用(能力有限自己寫不出來-_-||),出處爲每部分最後的鏈接,部分有修改。
OpenAI CEO Sam Altman:AGI或將十年內出現
6月10日全天的“AI安全與對齊”論壇,OpenAI聯合創始人Sam Altman進行了开場主題演講——也是他第一次中國演講,雖然是线上。
演講圍繞模型的可解釋性、可擴展性和可泛化性給出了見解。隨後,Sam Altman和智源研究院理事長張宏江开展了尖峰問答,主要探討在當前的AI大模型時代,如何深化國際合作,如何开展更安全的AI研究,以及如何應對AI的未來風險。

精彩摘要:
當下人工智能革命影響如此之大的原因,不僅在於其影響的規模,也是其進展的速度。這同時帶來紅利和風險。
AI 帶來的潛在紅利是巨大的。但我們必須共同管理風險,才能達到用其提升生產力和生活水平的目的。
隨着日益強大的 AI 系統的出現,全球合作的賭注從未如此之大。大國意見分歧在歷史上常有,但在一些重要的大事上,必須進行合作和協調。推進 AGI 安全是我們需要找到共同利益點的最重要的領域之一。演講中,Altman多次強調全球AI安全對齊與監管的必要性,還特別引用了《道德經》中的一句話:千裏之行,始於足下。對齊仍然是一個未解決的問題。
想象一下,未來的 AGI 系統或許具有 10 萬行二進制代碼,人類監管人員不太可能發現這樣的模型是否在做一些邪惡的事情。
GPT-4 花了八個月的時間完成對齊方面的工作。但相關的研究還在升級,主要分爲擴展性和可解釋性兩方面。一是可擴展監督,嘗試用AI系統協助人類監督其他人工智能系統。二是可解釋性,嘗試理解大模型內部運作「黑箱」。最終,OpenAI的目標是,訓練AI系統來幫助進行對齊研究。

在被張宏江問及距離通用人工智能(AGI)時代還有多遠時,薩姆·奧特曼表示,“未來10年內會有超強AI系統誕生,但很難預估具體的時間點”,他也強調,“新技術徹底改變世界的速度遠超想象。”
當被問及OpenAI是否會开源大模型,Altman稱未來會有更多开源,但沒有具體模型和時間表。另外,他還表示不會很快有GPT-5。 會後,Altman發文對這次受邀來智源大會演講表示感謝。

圖靈獎得主楊立昆:GPT模式五年就不會有人用,世界模型才是AGI未來
深度學習三巨頭之一、圖靈獎得主楊立昆帶來了題爲《朝向能學習、思考和計劃的機器進發》( Towards Machines that can Learn, Reason, and Plan)的主題演講,他一如既往地質疑目前LLM的路线,提出了另一種會學習、推理、計劃的機器的思路:世界模型。

演講核心觀點:
AI 的能力距離人類與動物的能力,還有差距——差距主要體現在邏輯推理和規劃,大模型目前只能「本能反應」。什么是自監督學習?自監督學習是捕捉輸入中的依賴關系。
訓練系統會捕捉我們看到的部分和我們尚未看到的部分之間的依賴關系。目前的大模型如果訓練在一萬億個 token 或兩萬億個 token 的數據上,它們的性能是驚人的。
我們很容易被它的流暢性所迷惑。但最終,它們會犯很愚蠢的錯誤。它們會犯事實錯誤、邏輯錯誤、不一致性,它們的推理能力有限,會產生有害內容。由此大模型需要被重新訓練。
如何讓 AI 能夠像人類一樣能真正規劃?可以參考人類和動物是如何快速學習的——通過觀察和體驗世界。
楊立昆認爲,未來 AI 的發展面臨三大挑战:學習世界的表徵、預測世界模型、利用自監督學習。
由此,楊立昆提出「世界模型(World Model)」,由六個獨立模塊組成,具體包括:配置器模塊、感知模塊、世界模型、cost模塊、actor模塊、短期記憶模塊。他認爲,爲世界模型設計架構以及訓練範式,才是未來幾十年阻礙人工智能發展的真正障礙。
首先是學習世界的表徵和預測模型,當然可以採用自監督的方式進行學習。
其次是學習推理。這對應着心理學家丹尼爾·卡尼曼的系統1和系統2的概念。系統1是與潛意識計算相對應的人類行爲或行動,是那些無需思考即可完成的事情;而系統2則是你有意識地、有目的地運用你的全部思維力去完成的任務。目前,人工智能基本上只能實現系統1中的功能,而且並不完全;
最後一個挑战則是如何通過將復雜任務分解成簡單任務,以分層的方式運行來規劃復雜的行動序列。
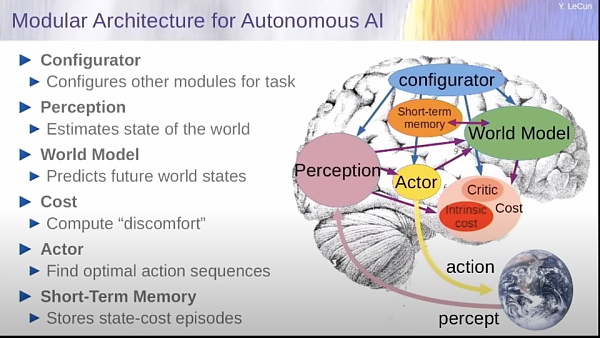
對於AI毀滅人類的看法,LeCun一直表示不屑,認爲如今的AI還不如一條狗的智能高,這種擔心實屬多余。被問到AI系統是否會對人類構成生存風險時,LeCun表示,我們還沒有超級AI,何談如何讓超級AI系統安全呢?
「今天問人們,我們是否能保證超級智能系統對人類而言是安全,這是個無法回答的問題。因爲我們沒有對超級智能系統的設計。因此,在你有基本的設計之前,你不能使一件東西安全。這就像你在1930年問航空工程師,你能使渦輪噴氣機安全和可靠嗎?而工程師會說,"什么是渦輪噴氣機?" 因爲渦輪噴氣機在1930年還沒有被發明出來。所以我們有點處於同樣的情況。聲稱我們不能使這些系統安全,因爲我們還沒有發明它們,這有點爲時過早。一旦我們發明了它們——也許它們會與我提出的藍圖相似,那么就值得討論。」
MIT人工智能與基礎交互研究中心教授 Max Tegmark:以機械可解釋性去掌控AI
Max Tegmark,現任麻省理工學院物理學終身教授、基礎問題研究所科學主任、生命未來研究所創始人、大名鼎鼎的“暫停AI研究倡議的發起人”(3月底的那份倡議書上有伊隆·馬斯克、圖靈獎得主Yoshua Bengio、蘋果聯合創始人史蒂夫·沃茲尼亞克等1000+名人的聯合籤名),在智源大會上做了一個精彩的演講,題目是《如何掌控AI》(Keeping AI under control),並與清華大學張亞勤院士進行了對話,共同探討AI倫理安全和風險防範問題。
演講詳細討論了AI的機械可解釋性,這實際上是研究,人類知識究竟是如何儲存在神經網絡裏那些復雜的連接關系裏的。這個方向的研究如果持續下去,或許最終可以真正解釋LLM大語言模型爲什么會產生智能這個終極問題。
演講之外,有趣的事實是,作爲“暫停AI研究倡議”發起人,主題演講卻是關注如何進行一個更深入的AI大模型研究。也許正如Max自己最後所說, 他並非AI三巨頭之一楊立昆教授所說的厄運者,他實際上對AI充滿希望和向往,只是我們可以確保所有這些更強大的智能爲我們服務,並用它來創造一個比科幻作家過去夢想的更鼓舞人心的未來。
注:本來以爲會很枯燥,意外地非常精彩,津津有味地看完一個小時的最長演講!不愧是經常講課的教授,非常引人入勝,也非常有理論深度,而且深入淺出。更令人驚喜的是不僅不是古板的 AI 反對者,其實還是個更好的AI的倡導者!還會說中文,一邊演講還不忘一邊給自己招生……

精彩觀點摘錄:
1、機械可解釋性是一個非常有趣的領域。你訓練一個你不理解的復雜神經網絡來執行智能任務,然後嘗試弄清楚它是如何做到的。
我們要這樣如何做?您可以有三個不同層次的抱負。最低層次的抱負是僅對其可信度進行診斷,了解您應該信任它多少。例如,當您开車時,即使您不了解剎車的工作原理,您至少希望知道是否可以相信它會減速。
下一個層次的抱負是更好地理解它,以使其更加可信賴。最終的抱負是非常雄心勃勃的,這也是我期望的,那就是我們能夠從機器學習系統中提取出它們學到的所有知識,並在其他系統中重新實現它們,以證明它們將按照我們的意愿行事。
2、讓我們慢下來,讓我們確保我們开發出更好的護欄。所以這封信說讓我們暫停一下,前面提到過。我想說清楚,它並沒有說我們應該暫停人工智能,它並沒有說我們應該暫停幾乎任何事情。到目前爲止,我們在這次會議上聽說過,我們應該繼續做幾乎所有你們都在做的精彩研究。它只是說我們應該暫停,暫停开發比GPT-4更強大的系統。所以這對一些西方公司來說主要是一個暫停。
現在,原因是這些正是系統,恰恰是可以使我們最快失去控制的系統,擁有我們還不夠了解的超級強大的系統。暫停的目的只是讓人工智能更像生物技術,在生物技術領域,你不能只說你是一家公司,嘿,我有一種新藥,我發現了,明天开始在北京各大超市銷售。首先你要說服中國政府或美國政府的專家,這是一種安全的藥物,它的好處大於壞處,有一個審查過程,然後你就可以做到。
讓我們不要犯那個錯誤,讓我們變得更像生物技術,使用我們最強大的系統,不像福島和切爾諾貝利。
3、張亞勤:好吧,Max,你的職業生涯是在數學、物理、神經科學,當然還有人工智能方面度過的。顯然,在未來,我們將越來越依賴跨學科的能力和知識。我們有很多研究生,很多未來的年輕人。
在年輕人如何做出職業選擇方面,您對他們有何建議?
Max Tegmark:首先,我的建議是在人工智能時代,專注於基礎知識。因爲經濟和就業市場的變化會越來越快。因此,我們正在擺脫這種學習12年或20年,然後余生都做同樣事情的模式。它不會是那樣的。
更重要的是,你要有扎實的基礎,並且非常善於創造性、思想开放的思維。這樣才能身手敏捷,隨波逐流。
當然,要關注整個人工智能領域正在發生的事情,而不僅僅是在你自己的領域。因爲在就業市場上,首先會發生的事情不是人被機器取代。但不與人工智能打交道的人將被與人工智能打交道的人所取代。
我可以再添加一點嗎?我看到時間在那裏閃爍。
我只想說一些樂觀的話。我覺得Yann LeCun是在取笑我。他稱我爲厄運者。但如果你看看我,其實我很开心很开朗。對於我們理解未來AI系統的能力,我實際上比Yann LeCun更樂觀。我認爲這是非常非常有希望的。
我認爲,如果我們全速前進,將更多的控制權從人類手中交給我們不了解的機器,那將以非常糟糕的方式結束。但我們不必那樣做。我認爲,如果我們努力研究機械可解釋性和今天將在這裏聽到的許多其他技術主題,我們實際上可以確保所有這些更強大的智能爲我們服務,並用它來創造一個比科幻作家過去夢想的更鼓舞人心的未來。

對話Midjourney創始人:圖片只是第一步,AI將徹底改變學習、創意和組織
MidJourney 是當下最炙手可熱的圖片生成引擎,在 OpenAI 的 DALL·E 2 和开源模型 Stable Diffusion 等激烈競爭下,目前仍保持着多種風格生成效果的絕對領先。
Midjourney 是一家神奇的公司,11 人改變世界,創造偉大的產品,注定會成爲 Pre AGI 初年的佳話。
注:期待已久的Midjourney創始人、CEO David Holz和極客公園張鵬的對談,全英文,沒有字幕,沒想到完全聽得懂,還特別津津有味,因爲問答都太精彩了,尤其是David,回答的時候忍不住笑,笑起來像個天真爛漫的小孩,有過大團隊管理經驗的他說「我從不曾想過要一家公司,我想要有一個家。」,他帶着直到現在也只有20來人的Midjourney成爲舉世矚目的獨角獸,可能改變了未來創業公司的範式。
創業驅動力:解放人類的想象力
張鵬:在過去的 20 年裏,我認識了很多國內外的創業者。我發現他們有一些共同點,他們都有強烈的驅動力,驅使他們「無中生有」地探索創造。
我想知道,在你創立 MidJourney 的時候,你的驅動力是什么?在那個時刻,你渴望的東西是什么?
David Holz:我從來沒有想過要創辦一家公司。我只是想要一個「家」(home)。
我希望在未來 10 年或 20 年,可以在 Midjourney 這裏創造那些我所真正關心的和真正想爲這個世界帶來的東西。
我經常思考各種各樣的問題。也許我不能解決每個問題,但是我可以做出一些嘗試,從而讓大家都能更有能力地解決問題。
因此,我嘗試去思考如何解決,如何創造東西。我認爲,這可以歸結爲三點。首先,我們必須反思自己:我們想要什么?問題究竟是什么?然後我們要想象:我們前進的方向在哪裏?有什么可能性?最後,我們必須相互協調,與他人合作,共同實現我們所想象的事情。
我認爲,在人工智能方面,有很大的機會將這三部分結合起來,並創造出重要的基礎設施,使我們更擅長於解決這個問題。在某種程度上,人工智能應該能夠幫助我們反思自己、更好地想象未來的方向、幫助我們更好地找到彼此並合作。我們可以一起完成這些事情,並將它們融合到某種單一的框架中。我認爲這將改變我們創造事物和解決問題的方式。這就是我想做的 big thing。
我認爲有時候(我們先做的)圖片生成可能會讓人感到困惑,但在許多方面,圖片生成是一個已被認可的概念。Midjourney 已經成爲了一個超級想象力的集合,數百萬人共同探索着這個空間的可能性。
在未來幾年裏,會有機會進行更多的視覺和藝術探索,這可能會超過所有先前歷史的探索總和。
這並不能解決我們面臨的所有問題,但我認爲這是一次測試,一次實驗。如果我們能完成這次視覺領域的探索,那么我們也可以在其他事情上做到,其他所有需要我們一起探索和思考事情,我認爲都可以通過類似的方式來解決。
因此,當我考慮如何开始着手解決這個問題時,我們有很多想法,建了很多原型,但是 AI 領域突然出現了突破性的進展,尤其是視覺方面,我們意識到這是一個絕無僅有的機會,能創造出一些別人從未嘗試過的東西。這讓我們想去爲之嘗試。
我們認爲,也許過不了多久,這一切都將匯聚到一起,形成非常特別的東西。現在還只是個开始。
張鵬:所以,圖片(生成)只是第一步,你的最終目標是解放人類的想象力。這是吸引你創立 Midjourney 的目標嗎?
David Holz:我真的很喜歡具有想象力的東西。我也希望這個世界能有更多的創意。每天都能看到瘋狂的想法,這太有趣了。
重新理解知識:歷史知識成爲創造的力量
張鵬:這很有趣。我們通常說空口無憑,給我看你的代碼(Idea is cheap, show me the code)。但現在,想法似乎才是唯一重要的東西。只要你能通過一系列優秀的 Prompt 表達你的想法,AI 就可以幫助你實現。所以,學習和創造的定義是否正在改變?你怎么看?
David Holz:我覺得一個有趣的事情是,當你給人們更多的時間去創造時,他們也會對學習本身更感興趣。
例如,美國有一種很流行的藝術風格叫做裝飾藝術。我從來沒有關心過這種藝術是什么,直到有一天,我通過指令就可以制作出這類藝術風格的作品時,我突然對它產生了很大的興趣,想更多了解它的歷史。
我覺得這是很有趣的一點,當歷史成爲你可以立即用起來並讓你更簡單地去創造的東西時,我們反而會對歷史更感興趣。如果用戶交互界面變得足夠好,讓用戶覺得 AI 成爲了我們思維的延伸。AI 就仿佛是我們身體和思想的一部分,AI 又在一定程度上與歷史緊密相連,而我們也將與歷史緊密聯系在一起。這太有意思了。
當我們問用戶他們最想要什么時,通常排在第一第二的回復是他們想要學習材料,他們不僅是想要學習如何使用工具,還想要了解藝術、歷史、相機鏡頭、光彩,想要了解和掌握所有可用於創造的知識和概念。
以前,知識只是過往的歷史,但現在,知識成爲了創造的力量。
知識在當下就能立即發揮出更大的作用,人們都渴望獲得更多的知識。這可太酷了。
Brian Christian:《人機對齊》中文版新書發布
《人機對齊》中文版書籍發布,作者Brian Christian用10分鐘簡要介紹了整本書的主要內容,聽起來內容非常豐富和精彩,也和當下AI的飛速發展非常呼應。
Brian Christian是一位獲獎無數的科學作者。他的作品《算法之美》曾被評爲亞馬遜年度最佳科學書籍和《麻省理工科技評論》年度最佳書籍。他的新書《人機對齊》(The Alignment Problem: Machine Learning and Human Values)目前正在被翻譯成中文,被微軟首席執行官薩蒂亞·納德拉評爲2021年激勵他的五本書之一。

《人機對齊》書分爲3個部分。
第一部分探討了影響當今機器學習系統的倫理和安全問題。
第二部分被稱爲代理,它將重點從監督和自我監督學習轉移到強化學習。
第三部分建立在監督、自我監督和強化學習的基礎上,討論我們如何在現實世界中對齊復雜的AI系統。
北京大學人工智能研究院助理教授楊耀東:大語言模型的安全性對齊進展綜述
注:北京大學人工智能研究院助理教授楊耀東做的《大語言模型的安全性對齊》演講很精彩,首先中文演講能聽懂,其次他用了非常通俗易懂的語言解釋了目前大語言模型安全對齊的主要研究進展,提綱挈領,在深度上超過很多講RLHF進展的內容。
因爲不懂詳細的技術,只能大概理解原理,記錄一些有意思的點:
OpenAI提出的3種Align的方式:
訓練AI使用人類反饋
訓練AI協助人類評估
訓練AI做對齊研究

AI大模型對齊市場仍是藍海:
現有大模型除GPT以外,幾乎都沒有成功實現任何意義上的對齊
大模型通用到專用的轉變技術,將是大模型發展的下一個制高點

3種對齊安全的方式:
在預訓練階段,通過人工篩選和數據清洗,獲取更高質量的數據
在輸出階段使用獎勵模型進行 reject sampling,提高輸出質量和安全性。或者在上线的產品中,拒絕回應用戶的輸入。
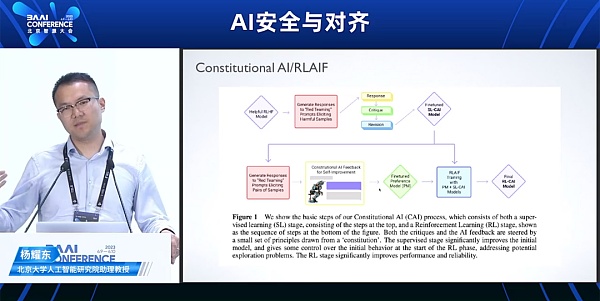
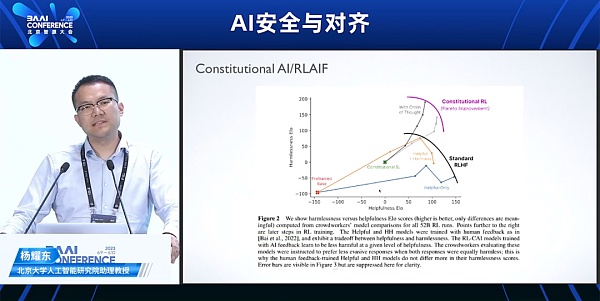
在微調 (SFT 和 BLHF) 階段,增加更加多元且無害的用戶指令和人類偏好模型進行對齊,包括RBRM、Constitutional Al。

從RLHF到RLAIF:Constitutional AI
圖靈獎得主 Geoffrey Hinton:超級智能將會比預期快得多,很擔心人類被它們控制
圖靈獎得主、「深度學習之父」Geoffrey Hinton壓軸演講,主題是Two Paths to Intelligence 通向智能的兩條通路。
AI教父帶給我們的是一項讓他相信超級智能將會比預期快得多的研究:凡人計算(Mortal Computation)。演講描述了一種新的計算結構,在拋棄了軟硬件分離的原則後,即不再用反向傳播描述神經網絡內部路徑的情況下,如何實現智能計算。


演講重點:
辛頓提出了一種全新的實現人工智能的可能:凡人計算。凡人計算讓軟硬件不再分離,用物理硬件更准確的做並行計算。它可以帶來更低的能耗和更簡單制作的硬件,但更難以訓練和擴展到大規模模型上。
智能群體共享知識的方式有兩種,生物性的和數字計算式的,生物性的共享帶寬低,很慢,數字拷貝帶寬高,且非常快。人是生物性的,而AI是數字性的,因此一旦AI通過多模態掌握更多知識,他們的共享速度很快,也會很快超越人類。
當AI進化到比人類更有智慧的時候,他們很可能會帶來巨大的風險。包括對人類的利用和欺騙,試圖獲取權力。並且很可能對人類的態度並不友好。
全新的計算模式之所以被Hinton稱爲 Mortal computation,寓意是深刻的:
1)之前Hinton說過,永生事實上已經實現。因爲當前的AI大語言模型已把人類知識學習到了千萬億的參數裏,且硬件無關:只要復刻出指令兼容的硬件,同樣的代碼和模型權重在未來都可以直接運行。在這個意義上,人類智慧(而不是人類)永生了。
2)但是,這種軟硬件分开的計算在實現的能量效率和規模上是極其低效的。如果拋棄硬件和軟件分離的計算機設計原則,把智能實現在一個統一的黑盒子裏,將是實現智能的一種新道路。
4)這種軟硬件不再分離的計算設計將極大幅度降低能耗和計算規模(考慮一下,人腦的能耗才20瓦)
5)但同時,意味着無法高效的復制權重來復制智慧,即放棄了永生。
人工神經網絡是否比真正的神經網絡更聰明?
如果一個在多台數字計算機上運行的大型神經網絡,除了可以模仿人類語言獲取人類知識,還能直接從世界中獲取知識,會發生什么情況呢?
顯然,它會變得比人類優秀得多,因爲它觀察到了更多的數據。
如果這個神經網絡能夠通過對圖像或視頻進行無監督建模,並且它的副本也能操縱物理世界——那這種設想並不是天方夜譚。

注:正當大家以爲演講興醬結束的時候,倒數第二頁,Hinton——用一種和之前所有科學家都不同的、有點情緒化、百感交集的口吻——說出了他對當下飛速發展的AI的擔憂,這也是在他最近毅然決然離开Google並「對自己畢生工作感到後悔,對人工智能危險感到擔憂」後,全世界都好奇的心聲:
我認爲這些超級智能的實現可能比我過去認爲的要快得多。
壞人們會想利用它們來做諸如操縱選民的事情。爲此,他們已經在美國和許多其他地方使用它們。而且還會用於贏得战爭。
要使數字智能更高效,我們需要允許其制定一些目標。然而,這裏存在一個明顯的問題。存在一個非常明顯的子目標,對於幾乎任何你想要實現的事情都非常有幫助,那就是獲取更多權力、更多控制。擁有更多控制權使得實現目標變得更容易。而我發現很難想象我們如何阻止數字智能爲了實現其它目標而努力獲取更多控制權。
一旦數字智能开始追求更多控制權,我們可能會面臨更多的問題。
作爲對比,人類很少去思考比自身更智能的物種,以及如何和這些物種交互的方式,在我的觀察中,這類人工智能已經熟練的掌握了欺騙人類的動作,因爲它可以通過閱讀小說,來學習欺騙他人的方式,而一旦人工智能具備了「欺騙」這個能力,也就具備前面提及的——輕易控制人類的能力。所謂控制,舉個例子,如果你想入侵華盛頓的一座建築物,不需要親自去那裏,只需要欺騙人們,讓他們自認爲通過入侵該建築物,就能實現拯救民主,最終實現你的目的(暗諷特朗普)。

這時,年過花甲、爲人工智能貢獻了畢生心血的 Gerffery Hinton 說:
「 我覺得很可怕,我不知道如何防止這種情況發生,但我老了,我希望像你們這樣的許多年輕而才華橫溢的研究人員會弄清楚我們如何擁有這些超級智能,這將使我們的生活變得更好,同時阻止這種通過欺騙實現控制的行爲……也許我們可以給他們設置道德原則,但目前,我還是很緊張,因爲到目前爲止,我還想不到——在智力差距足夠大時——更智能的事物,被一些反倒沒那么智能的事物所控制的例子。假如青蛙發明了人類,你覺得誰會取得控制權?是青蛙,還是人?這也引出我的最後一張PPT,結局。」
聽的時候我仿佛在聆聽「曾經的屠龍少年,人到暮年、回首一生時發現自己竟養出了惡龍時,發出的末日預言」,剛好夕陽西下, 我第一次深刻認識到AI對人類的巨大風險,無限唏噓。
和Hinton相比,更年輕的深度學習三巨頭之一 Lecun 顯然更樂觀:
被問到AI系統是否會對人類構成生存風險時,LeCun表示,我們還沒有超級AI,何談如何讓超級AI系統安全呢?
讓人想到《三體》裏地球人對三體文明的不同態度……
那天我還在無限唏噓的情緒中打算關掉電腦,沒想到,最後上場的智源研究院院長黃鐵軍做了一個完美的閉幕致辭:《無法閉幕》。
黃鐵軍首先總結前面大家演講的觀點:
AI越來越強,風險顯而易見,與日俱增;
如何構建安全AI,我們知之甚少;
可以借鑑歷史經驗:藥物管理、核武管控、量子計算......
但是高復雜度AI系統難以預測:風險測試、機制解釋、理解泛化……剛开始
全新挑战目標:AI服務自己目標還是人類目標?
本質上,人們要建設GAI通用人工智能還是AGI人工通用智能?
學術上的共識是AGI人工通用智能:在人類智能所有方面都達到人類水平,能夠自適應地應對外界環境挑战完成人類能完成的所有任務的人工智能;也可以叫自主人工智能、超人智能、強人工智能。
一方面,大家對建設通用人工智能熱情高漲、投資趨之若鶩,
另一方面,對AI導致人類成爲二等公民嗤之以鼻,但這樣的二元對立還不是最難的,大不了投票,難的是,面對類似ChatGPT這樣的類人工智能Near AGI,我們應該怎么辦?
如果人類以和投資建設人工智能一樣的熱情應對風險,那也許還有可能實現安全的人工智能,但你相信人類能做到嗎?我不知道,謝謝!
標題:智源大會2023觀後感:對AI更有信心 也更擔心人類了
地址:https://www.coinsdeep.com/article/15265.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。