零知識處理單元(ZPU)設計方案介紹—— 多功能及可編程的ZK硬件加速器
發表於 2023-07-10 08:30 作者: MarsBit
作者:Ingonyama,Medium;編譯:Kate, Marsbit
TL;DR:
在本博客中,我們提出了零知識處理單元(ZPU),這是一種通用的可編程硬件加速器,旨在解決零知識處理的新需求。
我們將介紹ZPU架構和設計注意事項。我們解釋了ZPU生態系統不同部分背後的設計選擇:ISA,數據流,內存和處理元件(PE)內部結構。最後,我們將 ZK 和全同態加密 (FHE) 與最先進的 ASIC 架構進行比較。
介紹
數據驅動的應用程序的快速增長和對隱私的日益增長的需求導致了對保護敏感信息的加密協議的興趣激增。在這些協議中,零知識證明(ZKP)作爲確保計算完整性和隱私性的強大工具脫穎而出。ZKP使一方能夠在不泄露任何額外信息的情況下向另一方證明聲明的有效性。這一特性導致ZKP在各種以隱私爲重點的應用中得到廣泛採用,包括區塊鏈技術、安全雲計算解決方案和可驗證的外包服務。
然而,在實際應用程序中採用ZKP面臨着一個重大挑战:與證明生成相關的性能开銷。ZKP算法通常涉及對非常大的整數的復雜數學運算,例如橢圓曲线上的大型多項式計算和多標量乘法。此外,密碼算法在不斷發展,新的和更有效的方案正在快速發展。因此,現有的硬件加速器很難跟上各種各樣的加密原語和不斷變化的加密算法。
在這篇博客中,我們提出了零知識處理單元(ZPU),這是一種新穎的多功能硬件加速器,旨在解決零知識處理的新需求。ZPU建立在指令集架構(ISA)上,支持可編程性,使其能夠適應快速發展的加密算法。ZPU 具有處理元件 (PE) 的互連網絡,具有對大字模塊化算法的本地支持。PE的核心結構受到乘法累加(MAC)引擎的啓發,該引擎是數字信號處理(DSP)和其他計算系統中的基本處理元素。PE的運算符使用模塊化算法,其核心組件專門用於支持ZK算法中的常見運算,例如NTT蝴蝶運算和用於多標量乘法的橢圓曲线點加法。
指令集架構
ZPU架構的特點是一個由指令集架構(ISA)定義的處理元件(PE)的互連網絡,如下圖1所示。我們選擇這種架構是爲了適應零知識協議不斷變化的環境。
ISA 方法使 ZPU 能夠保持靈活性,適應ZK算法的變化,並支持廣泛的加密原語。此外,使用ISA而不是固定的硬件可以在制造後持續改進軟件,確保即使在該領域出現新的進展,ZPU也能保持相關性和效率。
ISA是處理器可以執行的一組指令。它作爲硬件和軟件之間的接口,定義了軟件與硬件交互的方式。通過定制ISA來設計ZPU,我們可以針對ZK處理任務的特定要求對其進行優化,例如大字模算術運算、橢圓曲线加密和其他復雜的密碼運算。
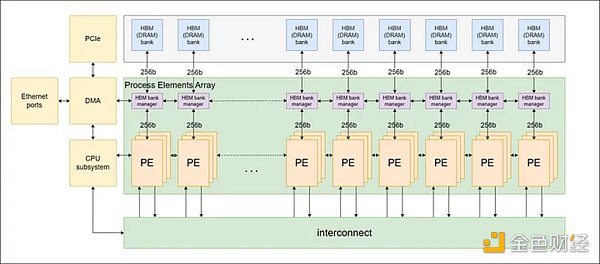
圖1:PE網絡結構
PE核心部件
每個PE都設計了一個內核,其中包括模乘法器、加法器和減法器,如圖2所示。這些核心組件的靈感來自數字信號處理(DSP)和其他計算系統的基本處理元件,乘法累加(MAC)引擎。MAC引擎有效地執行乘法累加運算,包括將兩個數字相乘並將乘積加到累加器中。
PE的核心結構是爲ZK中常見的運算量身定制的,例如用於多標量乘法的橢圓曲线點加法和用於數論變換(NTT)的NTT蝴蝶運算。蝴蝶運算包括加法、減法和乘法,都是在模運算下進行的。該操作的名稱來源於其計算流程圖的蝴蝶外觀,它非常適合PE的核心硬件組件,因爲它們通過專用的蝴蝶指令實現原生蝴蝶計算。
此外,每個PE包含幾個專用內存單元,包括:
1.到達休息室:用於存儲到達PE的數據的存儲器。
2.出發休息室:用於存儲從PE出發的數據的存儲器。
3.操作數A、B和C的暫存存儲器:三個單獨的存儲器用於存儲中間結果。
4.內存擴展器:用於處理各種算法需求的多用途內存,例如用於多標量乘法(MSM)的桶聚合。
5.程序存儲器:用於存儲指令隊列的存儲器。
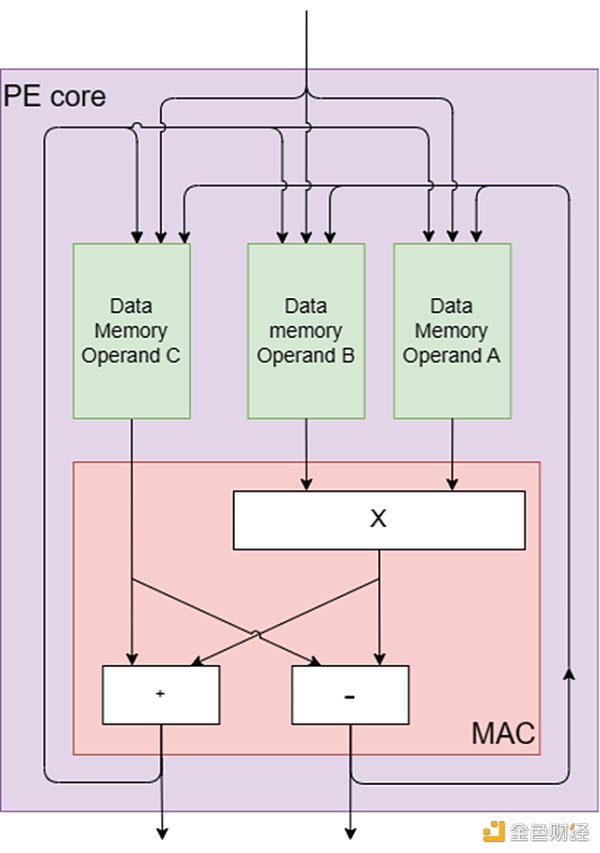
圖2:PE核心組件
PE位寬
PE本機支持大字模塊算術運算(最多256位字)。PE中高位寬本機支持和低位寬本機支持之間的權衡源於需要平衡不同操作數大小的效率。
當PE具有高位寬本機支持時,它會針對處理大操作數大小進行優化,而不需要將它們分解成更小的塊。然而,這種優化的代價是較小位寬操作的效率降低,因爲PE未得到充分利用。另一方面,當PE具有低位寬本機支持時,它被優化爲更有效地處理小操作數大小。然而,當處理較大位寬的操作時,這種優化會導致效率低下,因爲PE需要將較大的操作數分解成較小的塊,並依次處理這些塊。
挑战在於找到高低位寬本機支持之間的適當平衡,以確保在廣泛的操作數大小範圍內進行有效處理。這種平衡應該考慮目標應用程序領域(即ZK協議)中普遍存在的常見位寬度,並權衡每種設計選擇的優缺點。在ZPU架構的情況下,選擇256位字長作爲一個很好的平衡。
PE的連接
所有PE之間採用環形連接,每個PE直接與相鄰的兩個PE相連,形成一個環形網絡。這種環形連接允許控制數據在不同PE之間有效地傳播。PE也通過互連組件連接,這是一種類似於桶形移位器的機制,可以隨着時間的推移在不同的PE之間實現直接連接。這種設置允許PE發送和接收來自所有其他PE的信息。
周邊組件
該架構還集成了片外高帶寬內存(HBM),以支持高內存容量和高內存帶寬。將多個PE聚在一起組成一個PE集群,每個PE集群與一個HBM bank或信道相連。此外,還包括一個基於ARM的片上CPU子系統來管理整個系統操作。
績效評估
爲了評估ZPU的性能,我們考慮了我們旨在加速的算法的關鍵操作。我們主要研究的是NTT蝴蝶運算和橢圓曲线(EC)點加法運算。爲了評估MSM和NTT操作的總計算時間,我們計算了它們所需的計算指令的總量,並將它們除以時鐘頻率和PE的數量。
NTT 蝶形運算在每個時鐘周期執行。對於多標量乘法(MSM)中的關鍵元素橢圓曲线點加法運算,我們將其解構爲可以在單個PE上執行的基本機器級指令。我們隨後計算完成此操作所需的時鐘周期數。通過分析,我們確定每個橢圓曲线點相加運算可以每18個時鐘周期執行一次。
這些假設爲我們的性能評估提供了基礎,並且可以根據需要進行調整,以反映不同的算法要求或硬件功能。
根據我們的計算,在GPU的1.305 GHz頻率上運行72個PE的配置足以匹配Zprize的MSM操作中GPU類別獲勝者的性能。Yrrid Software和Matter Labs都實現了這一壯舉,使用A40 NVIDIA GPU每4次MSM計算達到2.52秒的結果。該比較基於固定基點 MSM 計算,涉及從 BLS 12-377 標量場中隨機選擇的 2²⁶ 標量,以及來自 BLS 12-377 G1 曲线的一組固定橢圓曲线點和有限的隨機採樣輸入向量來自標量場的場元素。
根據我們對PE的面積估計,使用8nm工藝的ASIC,與A40 GPU中採用的工藝技術相同,可以在與A40 GPU相同的628 mm2面積內容納大約925個PE。這意味着我們實現了比A40 GPU高約13倍的效率。
PipeZK是一種高效的流水线加速器,旨在提高零知識證明(ZKP)生成的性能,具有專用的MSM和NTT內核,分別優化了多標量乘法和大型多項式計算的處理。
與 PipeZK 相比,我們發現僅 17 個以 PipeZK 頻率 300 MHz 運行的 PE 的配置就足以匹配 PipeZK 的 MSM 操作性能。PipeZK在BN128曲线中的2²⁰長度的MSM上以 300 MHz 執行 MSM 操作,耗時0.061秒完成。此外,爲了匹配PipeZK的NTT操作性能,在300MHz下運行256位元素的2²⁰元素NTT,耗時0.011秒,我們需要大約 4 個以相同頻率運行的 PE。總的來說,爲了匹配PipeZK同時運行MSM和NTT的性能,我們需要21個PE。
根據我們的面積估計,使用28nm工藝的ASIC(與PipeZK中採用的工藝技術相同)可以在與PipeZK芯片相同的50.75 mm2面積內容納大約16個PE。這意味着我們的效率略低於PipeZK的固定架構(效率低25%),同時仍然可以完全靈活地適應不同的橢圓曲线和ZK協議。
環處理單元(RPU)是最近的一項工作,旨在加速基於環的帶錯誤學習(RLWE)的計算,這是各種安全和隱私增強技術的基礎,如同態加密和後量子加密。
與RPU相比,我們的計算表明,當計算128位元素的64K NTT時,爲了匹配RPU在最佳配置(128 bank和HPLEs)下的性能,我們將需要大約23個PE在RPU的1.68GHz頻率上運行。我們的分析表明,採用與RPU相同的12nm工藝技術的ASIC可以在RPU佔用的20.5 mm²面積內容納大約19.65個PE。這意味着我們的效率略低於RPU(效率低15%),同時與NTT以外的原語兼容。
TREBUCHET是一個完全同態加密(FHE)加速器,它使用環處理單元(RPU)作爲片上區塊。切片還通過將數據調度到接近計算元素的位置來促進內存管理。RPU在整個設備中被復制,使軟件能夠最大限度地減少數據移動並利用數據級並行性。
TREBUCHET和ZPU都基於ISA架構和大型算術單詞引擎,這些引擎在模塊化算法下支持非常長的單詞(128位或更高)。然而,與RPU或TREBUCHET SoC相比,ZPU的附加價值在於它擴大了該架構旨在解決的問題集。RPU和TREBUCHET主要關注NTT,而ZPU支持更多的原語,如多標量乘法(MSM)和面向算術的哈希函數。
總結
我們的性能評估表明,ZPU可以匹配甚至超過現有最先進的ASIC設計的性能,同時對ZK算法和加密原語的變化提供更大的適應性。雖然需要考慮權衡,例如PE 中高位寬和低位寬支持之間的平衡,但ZPU的設計經過精心優化,以確保在廣泛的操作數尺寸範圍內進行高效處理。對於那些有興趣了解更多關於ZPU或探索潛在合作的人,請隨時與我們聯系。我們期待與大家分享更多關於ZPU項目進展和未來發展的最新信息。
標題:零知識處理單元(ZPU)設計方案介紹—— 多功能及可編程的ZK硬件加速器
地址:https://www.coinsdeep.com/article/21079.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。