人工智能與工作自動化
發表於 2023-09-09 16:20 作者: 區塊鏈情報速遞pro
幾乎科技界的每個人都同意,對於我們可以用軟件做什么以及我們可以用軟件自動化做什么來說,生成式人工智能、大語言模型以及 ChatGPT 屬於代際變化。關於大語言模型的其他問題並沒有達成太多共識——事實上,我們仍在研究爭論的焦點是什么——但每個人都同意會出現更多的自動化,以及全新類型的自動化。而自動化意味着崗位,以及人。
這種情況的進展速度也非常快:僅僅六個月後,ChatGPT 就擁有了(顯然) 1 億以上的用戶,而來自Productiv的數據表明,它已經是排名前十的“影子 IT” app(編者按:指的是沒有經過正式批准就被員工使用的app)。那么,這會奪走多少工作崗位,速度有多快,是否會有新的工作崗位來取代它們?
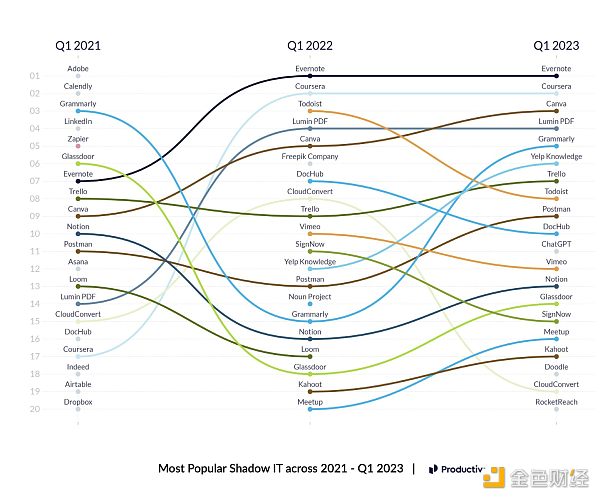
最近幾年最熱門的影子IT應用
首先我們應該記住的是,工作自動化的進程已經有 200 年了。每當我們經歷一波自動化浪潮時,就會有一整個類別的工作會消失,但新的工作門類也會被創造出來。在這個過程當中會存在陣痛和錯位,有時候新的工作崗位會分配給不同地方不同的人,但隨着時間的推移,工作崗位總數不會下降,我們會變得更加繁榮富足。
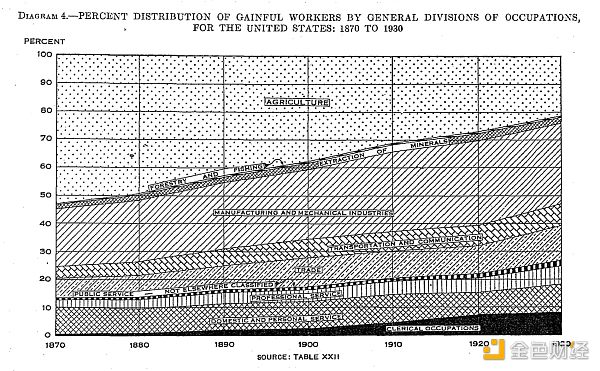
美國人口普查(按行業),1870年—1930年
當這種情況發生在你們這一代人身上時,人們自然而然地會擔心這一次不會再有新的工作崗位出現。我們可以看到一些工作崗位正在消失,但我們無法預測新的工作崗位會是什么,而且通常它們還不存在。根據經驗,我們知道(或應該知道),過去總會有新工作出現,而且這些工作也是不可預測的:1800 年的時候,沒人會預測到 1900 年有一百萬美國人從事“鐵路”工作, 1900 年的時候,沒人會預見到“視頻後期制作”或“軟件工程師”會成爲一個工作類別。但僅僅因爲過去一直都這樣,就相信這種情況現在還會發生似乎還不夠。你怎么知道這次會延續之前的情況呢?這次會不一樣嗎?
在這一點上,任何一位一年級的經濟學學生都會告訴我們,這個問題這樣子回答是犯了“勞動合成”(Lump of Labour)謬誤。
勞動總量謬誤是這樣一種謬誤,即認爲社會中需要做的工作總量是固定的,如果機器承擔了部分工作,那么留給人類的工作就會減少。但是,如果用機器制造一雙鞋變得更便宜的話,則鞋子就會變得更便宜,於是就會有更多的人可以購买鞋子,他們就可以留出更多的錢去花在其他東西上,我們就會發現我們需要或者想要的新東西或新的工作。效率的提升並不局限在鞋子上:一般來說,它會通過經濟向外擴散,創造新的繁榮和新的就業機會。因此,雖然我們不知道新的工作崗位會是什么,但我們知道這樣一個模式,它不僅能說明總會有新的工作崗位出現,而且還能說明爲什么這是這個過程中固有的現象。不用擔心人工智能!
我認爲,今天這個模式面臨的最根本的挑战是這樣一個說法:不對,過去 200 年的自動化的實質是我們一直在提高人類能力的規模。

“伏爾加河上的駁船搬運工”,伊利亞·列賓,1870-73。 (注意右側地平线上出現了冒煙的蒸汽船。)
作爲人類,我們是從做苦力的野獸开始,然後向上發展的:我們先是自動化了自己的腿,然後是手臂,然後是手指,現在是大腦。我們一开始從事的是農場工作,然後是藍領工作,再到白領工作,現在我們把白領工作也自動化了,已經沒有什么可以自動化了。工廠被呼叫中心取代,但如果我們連呼叫中心也自動化了,那人類還剩下什么可以做的?
關於這個問題,我認爲了解另一段經濟和科技史會有所幫助:傑文斯悖論(Jevons Paradox)。
19世紀的英國海軍還要靠燒煤來讓船跑起來。那時候英國擁有大量煤炭(那時候的英國就是蒸汽時代的沙特阿拉伯),但人們擔心煤炭耗盡後該怎么辦。呃,工程師們說:別擔心,因爲蒸汽機的效率會越來越高,所以我們使用的煤炭會越來越少。但傑文斯說,不:如果我們讓蒸汽機變得更高效,那么它們的運行成本就會更低,我們就會使用更多的蒸汽機,並將這些蒸汽機用於新的、不同的事物上,所以我們會使用更多的煤炭。創新可以與價格彈性建立關聯。
150 年來,我們一直將傑文斯悖論應用在白領工作上。

替代手工抄寫的打字機

替代人工簿記的加法機
還不存在的未來工作很難想象,但過去的部分工作已經被自動化所取代也很難想象。 在果戈裏的筆下,1830 年代被剝削的職員整個職業生涯都消耗在復印文件上,一次一份,全靠手工。他們就是人類復印機。到了 1880 年代,打字機已經可以以每分鐘兩倍字數的速度打印出清晰易讀的文本,而復寫機也能提供六份免費副本了。打字機意味着一名職員的產出量可以提高 10 倍以上。幾十年後,像 Burroughs 這樣的公司制造的加法機對簿記和會計也做了同樣的事情:你再也不用拿起筆進行累加了,而是用機器完成,時間只需要過去的20%,而且還不會出錯。
這對文員的就業有何影響?結果社會僱傭了更多的文員。自動化加上傑文斯悖論意味着創造出更多的就業機會。
如果配置了一台機器的文員可以完成過去 10 名文員所做的工作,那么你的文員可能會減少,但你也可能會用這些人做更多的事情。傑文斯告訴我們,如果做某事變得更便宜、更高效的話,你可能會做更多這樣的事情——你可能會進行更多的分析,或管理更多的庫存。你可能會建立一個不一樣的、更高效的企業,這之所以成爲可能,是因爲你可以用打字機和加法機實現業務管理的自動化。
歷史在不斷重復着這個過程。這是 1960 年《公寓》中傑克·萊蒙 (Jack Lemmon) 飾演的 CC Baxter,他使用的是 Friden 的機電加法機,五十年前,加法機才剛剛出現,令人興奮。

機電加法機
這個鏡頭裏面的每一個人都是電子表格中的一個單元格,整棟建築物則是一個電子表格。每周一次地,樓頂會有人按下 F9,然後他們就开始會重新計算。但他們已經有了計算機,並且到了 1965 年或 1970 年地時候,他們購买了一台大型機,並廢棄了所有的加法機。那白領崗位崩潰了嗎?或者,就像 IBM 所宣傳的那樣,計算機是不是給你額外增加了 150 名工程師? 25 年後,PC 革命以及小盒子內的會計部門對會計又產生了什么影響?

IBM稱擁有一台大型機相當於多了150名工程師

桌面版會計系統的廣告:一個小盒子取代一個會計部門
Dan Bricklin 在 1979 年發明了計算機電子表格:在那之前,“電子表格”都是紙質的(你仍然可以在亞馬遜上买到)。關於電子表格地早期使用,他講述了一些有趣地故事:“人們會這么告訴我,‘所有這些工作都是我做的,同事們認爲我很棒。但我其實很懶,因爲做完那些事情我只花了一個小時,然後剩下的時間我都是在休息。別人認爲我是神童,但我只是使用了這個工具罷了。”
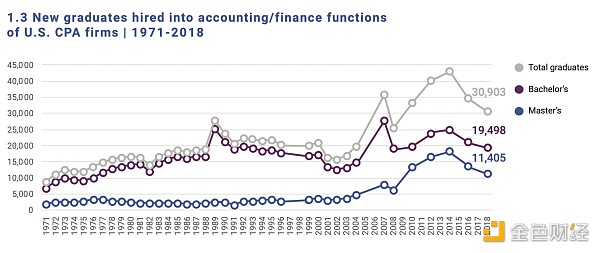
EXCEL、PC出現後,會計崗位不降反升
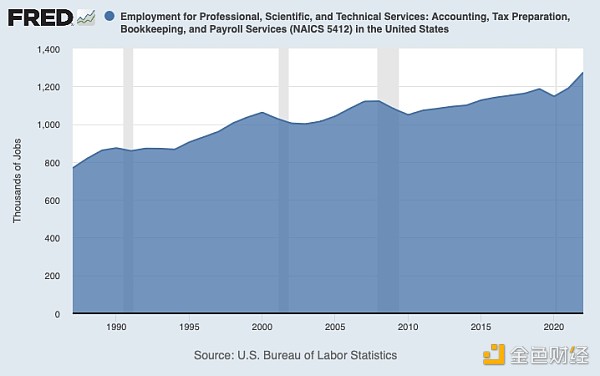
美國1990-2020年間會計、簿記、工資服務、納稅服務相關崗位情況
那么,Excel和PC對會計崗位有何影響呢?會計的崗位增加了。
40 年後,電子表格是不是意味着你可以早點休息了?其實不然。
年輕人可能不相信這一點,但在電子表格出現之前,投資銀行家的工作時間確實很長。多虧有了 Excel,高盛的員工才能完成所有工作並在周五下午 3 點離开辦公室。現在,大語言模型意味着他們每周只需工作一天!
新技術通常會讓做某件事情變得更便宜、更容易,但這可能意味着你可以用更少的人做同樣的事情,或者你可能也可以用同樣的人做更多的事情。它還往往意味着你改變了要做的事情。一开始,我們讓新工具適應舊的工作方式,但隨着時間的推移,我們开始改變工作方式來適應這個工具。當 CC Baxter 所在的公司購买大型機時,他們先是將現有的工作方式自動化,但隨着時間的推移,新的業務運營方式成爲可能。
因此,所有這一切都表明,默認情況下,我們應該期望大語言模型能夠像 SAP、Excel、大型機或打字機一樣顛覆、取代、創造、加速和增加就業機會。這只是有了更多的自動化。機器可以讓一個人完成十倍的工作,但你還是需要這個人。
對於這種看法,我認爲有兩個反駁論據。
第一條,是,也許這確實與我們從互聯網、個人電腦或PC上看到的變化更爲相似,或許着不會對淨就業產生長期影響,但這一次發生的速度會更快,因此帶來的陣痛會更大,調整起來也會更加困難。
LLM 與 ChatGPT 的發展速度肯定比 iPhone、互聯網,甚至個人電腦要快得多。 Apple II 的上市時間是 1977 年,IBM PC 上市時間爲 1981 年,Mac 上市時間爲 1984 年,但直到 20 世紀 90 年代初,PC 的使用量才達到 1 億台:但推出僅僅六個月後, ChatGPT 用戶數就達到了 1 億。你不需要等電信公司建立寬帶網絡,或者等消費者購买新設備,生成式人工智能,是建立在過去十年建立起來的一整個技術棧的基礎之上的:雲計算、分布式計算以及衆多機器學習技術棧。對於用戶來說,它只是一個網站。
如果你再思考一下來自Productiv和 Okta(了用不同方法)的這些圖表的意味時,你的預期可能會有所不同。他們這兩家公司報告稱,其典型客戶現在擁有數百種不同的軟件應用,而企業客戶擁有的軟件數量則有近 500 種。
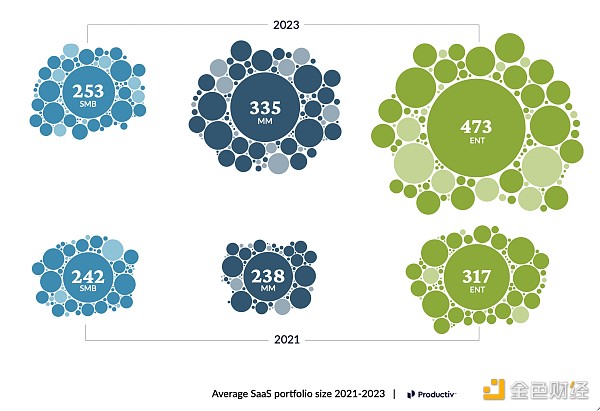
中小企業、大企業擁有的SaaS應用數量不斷增長
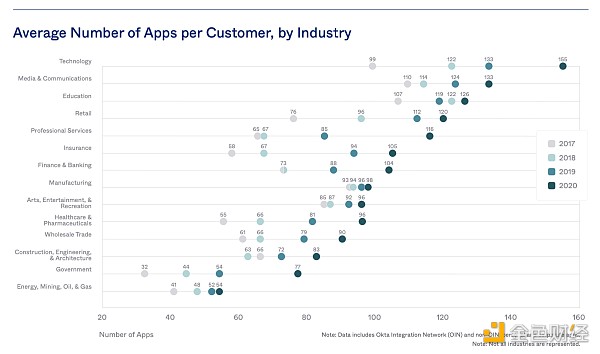
不同行業的平均app數量也是增長趨勢(每客戶)
可是,企業對雲計算的採用率仍僅佔工作流的四分之一。
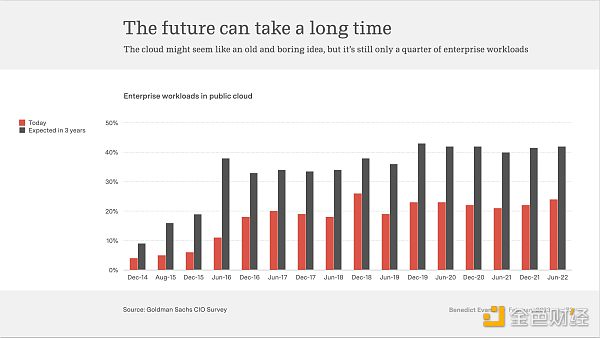
雲化的道路還很長
這對於工作場所的生成式人工智能意味着什么?不管你認爲會發生什么事情,其所需要的時間都會是數以年計,而不是以周計。
人們用來完成手頭工作的工具,以及某些現在可能會有一層新的自動化分擔的任務,是非常復雜且非常專業的,裏面可能集成了大量的工作和機構知識。很多人都在嘗試 ChatGPT,看看它能做什么。也許你就是其中之一。但這並不意味着 ChatGPT 已經取代了他們現有的工作流,替換或自動化掉這些工具和任務中的任何一個都不是小事。
變革性技術一次令人驚嘆的演示,與一家大型復雜公司持有的,別人的業務可以使用的東西之間存在巨大差異。你登門拜訪律師事務所時,很少只是爲了兜售一個 GCP (谷歌雲平台)的翻譯或情緒分析的 API 密鑰:你需要把它包裝進控制、安全、版本控制、管理、客戶權限以及只有法律軟件公司才知道的一大堆其他內容裏面(在過去十年的時間裏,很多機器學習公司已經認識到了這一點)。公司一般都沒法买“技術”。 Everlaw不賣翻譯,People.ai 也不賣情感分析——他們賣工具和產品,而人工智能通常只是其中的一部分。我不覺得文本提示、“开始”按鈕、黑箱、通用文本生成引擎能成爲產品,產品需要時間。
與此同時,購买管理大型復雜事物的工具也需要時間,哪怕這種工具已經开發出來並找到了產品市場匹配。要想做企業軟件初創企業,面臨的最基本挑战之一是初創公司的融資周期爲18 個月,而許多企業的決策周期就要 18 個月。 SaaS本身加速了這格周期,因爲你不需要進入企業數據中心的部署計劃,但你還是得購买、集成和培訓,而對於擁有數百萬客戶以及數萬或數十萬員工的公司來說,不要一下子就做出改變是有充分理由的。到達未來需要一段時間,硅谷以外的世界很復雜。
第二個反駁論據是,ChatGPT 和 LLM 範式轉變的一部分是抽象層的轉變:這看起來像是一種更通用的技術。確實,這就是它令人興奮的原因。他們告訴我們,它可以回答任何問題。因此,你可以看看那張圖裏面的473 個企業 SaaS 應用,然後說 ChatGPT 會顛覆這一切,然後將許多垂直應用折疊到一個提示框之中。這意味着它會發展得更快,並且自動化程度更高。
我認爲這是誤解了這個問題。如果律師事務所的合夥人想要一份文件的初稿,他們對參數調整的要求會與處理索賠的保險公司銷售人員完全不同,他們可能會使用不同的訓練集,當然還有一堆不同的工具。 Excel 也是“通用用途”工具,SQL 亦然,但是有多少種不同類型的“數據庫”呢?這就是我認爲大語言模型的未來會從提示框轉向 GUI 和按鈕的原因之一 —— 我認爲,“提示工程”與“自然語言”這兩個東西是相互矛盾的。但不管是哪一種,就算你可以在一個龐大的基礎模型之上把一切作爲一層薄薄的封裝來運行(而且對於這一點大家還沒有達成一致或明確),這些封裝也是需要時間的。
事實上,雖然有人可能會認爲大語言模型會在一個軸向上將許多應用納入其中,但我認爲,隨着初創公司從 Word、Salesforce 和 SAP 剝離出更多用例,它們同樣有可能在其他軸向上掀起一波全新的解綁浪潮,同時,通過解決在大語言模型讓你具備解決能力之前沒人意識到的問題來建立一大堆更大的公司。畢竟,這個進程解釋了爲什么大公司如今會擁有 400 個 SaaS 應用。
當然,更根本的問題是錯誤率。 ChatGPT 是“任何問題”都可以回答,但答案可能是錯的。大家稱之爲幻覺、編造事實、撒謊或胡說八道——這就是“過於自信的大學生”問題。但我認爲這樣的思維框架沒什么幫助:我認爲理解這一點的最好辦法是,當你在提示框輸入某些內容時,其實根本就沒有要求它回答問題。相反,你想問的是“人們可能會對這樣的問題給出什么樣的答案?”你要求它匹配一個模式。
因此,如果我讓 ChatGPT4 寫一篇我自己的傳記,然後再問它,它會給出不同的答案。它會說我上過劍橋、牛津或倫敦經濟學院(LSE);我的第一份工作是做股票研究、咨詢或財經新聞。這些總是對的模式:正確的大學類型,正確的工作類型(它從來沒說我上過麻省理工學院,然後第一份工作是餐飲管理)。對於“像我這樣的人可能拿到的是什么類型的學位,從事什么樣的工作?”這個問題,它給出了 100% 正確的答案。對於這個問題,它不是在進行數據庫查詢:而是在創建一個模式。
這張圖是我用MidJourney生成的,換你來也能得出類似的內容。提示詞是“戛納國際創意節,海灘邊,廣告從業人員在研討會台上討論創意的照片。”

圖片與模式幾乎完美匹配——看起來很像戛納的海灘,這些人的服裝很像廣告人,連發型也很合適。但它什么都不知道,所以它不知道人從來沒有三條腿,只知道這不太可能。這不是“撒謊”或“編造”——它是在匹配一個模式,只不過不夠完美。
不管你怎么稱呼它,如果你不理解這一點,你就會遇到麻煩,就像這位不幸的律師所經歷的情況那樣,他不明白,當他要求提供判例時,他其實是在要求看起來像判例的東西。他適時地得到了看似是判例的東西,但事實並非如此。它不是數據庫。
如果你確實明白了這一點,那你就得問一個問題,LLM 有什么用處?把本科生或實習生(這些人可以重復你可能需要檢查的模式)自動化有什么用處?上一波機器學習給你帶來了無數的實習生,這些實習生是可以替你閱讀任何東西,但你必須檢查,現在我們有了無數可以爲你寫任何東西的實習生,但你也必須檢查。那么這些數量無限的實習生有什么用呢?問問Dan Bricklin——我們又回到了傑文斯悖論。
顯然,話題就講到了通用人工智能(AGI)。對於我剛才所說的一切,真正根本的反駁是提問,如果我們有一個錯誤率爲零、沒有幻覺,並且確實可以做人可以做的任何事情的系統的話,情況會怎么樣?如果我們有了這個東西,那你可能不需要一名產出相當於十名普通會計,會用EXCEL的會計了:你可能只需要那台機器就行了。那么這一次的話,情況也許真的會有所不同。以前的自動化浪潮意味着一個人可以做更多的事情,但現在你已經不需要這個人了。
不過,就像許多 AGI 問題一樣,如果你不小心的話,這可能會變成一個死循環。 “如果我們有一台可以做人能做的任何事情的機器,又沒有任何這些限制的話,那么它會做人能做的任何事情,並且沒有這些限制嗎?”
嗯,確實,如果是這樣的話,我們可能會遭遇的問題就比中產階級就業問題還要大,但我們距離這個已經很接近了嗎?也許就算你用了幾周的時間仔細觀看計算機科學家爭論這個問題的三個小時 YouTube 視頻,最後得出的結論也是他們其實也不知道。你可能還會認爲,這個神奇的軟件將改變一切,並超越真實的人、真實的公司以及實體經濟的各自復雜性,並且現在可以在幾周而不是幾年之內部署,這聽起來像是經典的技術解決主義,但從烏托邦變成了反烏托邦。
不過,作爲一名分析師,我更傾向於認可休謨的經驗主義而不是笛卡爾的哲學——我只能分析我們所能知道的東西。我們還沒有通用人工智能,在沒有通用人工智能的情況下,我們就只會有另一波的自動化浪潮,而且我們似乎沒有任何先驗的理由來解釋爲什么這次就一定會比之前的其他所有浪潮多多少少要更痛苦些。
標題:人工智能與工作自動化
地址:https://www.coinsdeep.com/article/42544.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。