Dune SQL 和以太坊數據分析進階指南
發表於 2023-09-11 13:55 作者: 區塊鏈情報速遞pro
作者:ANDREW HONG;來源:Web3 Data Degens;編譯:登鏈翻譯計劃
在本指南中,你將學習如何瀏覽以太坊協議標准,並在調用跟蹤、時間序列余額跟蹤、dex/nft 交易和 ABI 上使用高級 SQL 函數。
什么是標准?如果我是分析師,爲什么它們很重要?
協議包含一套智能合約,用於有效管理功能、狀態、治理和可擴展性。智能合約可以無限復雜,一個函數可以調用幾十個其他合約。這些合約結構會隨着時間的推移而演變,其中一些最常見的模式會成爲標准。以太坊改進提案(EIPs)會對標准進行跟蹤,創建一套實現參考(代碼片段庫)。
以下是一些成爲了標准的例子:
創建克隆的工廠(如Uniswap factory創建新的交易對合約或Argent創建智能合約錢包),已經更進一步的最小代理(EIP-1167)的優化。
像WETH、aTokens這樣的存款/取款代幣,甚至像 Uni-v2 這樣的 LP 持倉都成了代幣金庫(EIP-4626)。
ENS、Cryptopunks、Cryptokitties 和其他非同質代幣誕生了今天的 NFT 標准(EIP-721)。此後又有許多改進的實現方案,如ERC721A。
上述標准只是無需更改以太坊虛擬機(EVM)的實現的協議(合約)。這些被稱爲 ERC 標准。
還有一些標准,如在半特定地址上部署合約,從而在 EVM 層面添加了 CREATE2 操作碼(EIP-1014),使其成爲 CORE 標准。這樣,我們就能讓 Opensea 在所有鏈上的同一地址部署 Seaport(讓每個人更方便)。
我建議你從主要的 ERC 標准入手,了解每個標准的最佳示例合約。你可以在我的儀表板中了解這些標准,其中涵蓋了每一種標准:
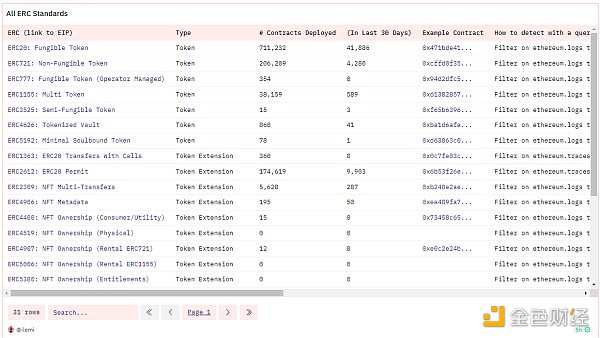
每個 ERC/EIP 解釋,附趨勢和示例(#1)
這些標准之所以重要,是因爲它們在所有協議中通用。無論增加了什么獨特的復雜性,如果是一個 DEX,那么你就知道首先要尋找 ERC20 代幣的流動性在哪,並尋找進出該流動性池的一些轉账。然後,你就可以從中拼湊出復雜的協議。
許多模式,如oracles 和利用率曲线,尚未成爲 EIP 標准。 EIP 也不是唯一可以找到標准的地方,你還可以通過 Opensea 的Seaport 改進提案 (SIP)等在協議層面找到一些標准。
如果你以 "他們在現有模式的基礎上構建了什么 "的思維方式來處理協議,那么你的分析師生活將會變得更加輕松有趣。
爲簡單起見,在本文的其余部分,我將把模式稱爲 "標准"。
Spellbook 表和查詢分析是標准的抽象
標准先行的方法還能讓我們更容易理解 Spellbook 表和其他分析師的查詢。我們以 dex.trades 爲例。我有一些假定:即 DEX 必須遵循這些標准模式中的大部分,才能與生態系統的其他部分保持兼容。
下面是我查看 dex.trades 表上的新 DEX 時的檢查清單示例:
標准:你可以用一個 ERC20 代幣兌換另一個 ERC20 代幣。我們將每次兌換在表中表示爲一行。
標准:流通量必須已經存在某個地方,很可能在某個類似於 ERC4626 的保險庫合約中(其中一些新代幣代表存入的流通量)。
深入:我們喜歡將最能代表“兌換代幣對”的 "流動性合約" 放在 project_contract_address列中。
**標准:**流動性合約持有兩個或多個代幣。
深入:我會將 project_contract_address 輸入 Etherscan,看看該合約持有哪些代幣(如果持有的話,有些合約如 Balancer v2 ,在池上使用的內部余額跟蹤)。
標准: 這種流動性合約通常由工廠生產。
深入:然後,我會點擊進入 project_contract_address 創建交易鏈接,並注意是否有工廠合約。如果沒有,那么這就向我表明,每個交易對可能真的很復雜--或者它只支持某一種代幣/機制。
標准:用戶通常會調用一些 "路由器"合約,而不是流動性合約(ETH → USDC,然後 USDC → Aave,完成 ETH → Aave 交換)。
深入:某個用戶(錢包籤名者)調用的頂層合約是 tx_to 。在第一個調用的合約和實際流動性合約(project_contract_address)之間有多少個合約調用?
頂層合約是與 DEX/聚合器相關,還是像 ERC4337 那樣更復雜?
標准:不同的 DEX 可針對不同類型的代幣進行優化
深入:賣出(換入)或买入(換出)代幣的地址分別爲token_sold_address和token_bought_address。
通常买入/賣出什么樣的代幣?(rebase 型、穩定幣、波動型等)。
該代幣來自哪裏?是普通的 ERC20 還是更特殊的包裝?
有些代幣有額外的轉账邏輯。我會檢查交易日志,看看這兩種代幣是否發生了特殊事件。
標准:與激勵資金池流動性掛鉤的收益耕作/獎勵標准
深入:再次查看 "project_contract_address"創建交易鏈接,看看初始交易是否創建了其他合約。
在查看這份清單的過程中,我使用 EVM 快速入門儀表板 記下有趣的交易示例和表格。
還有一篇文章:如何在五分鐘內分析任何以太坊協議或產品
我還建立了一些輔助查詢,比如這個 交易瀏覽器查詢,它可以顯示針對給定交易哈希值要查詢的所有表:
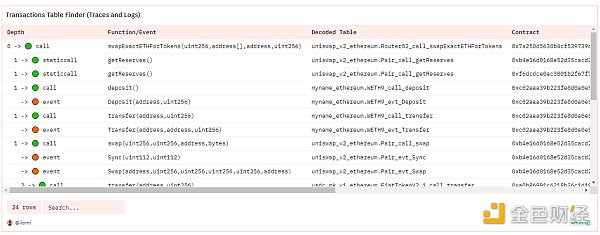
標准優先的分析方法加深了我在現有 DEX 標准背景下對這種新 DEX 的理解。
挑战: 去試試 12 Days of Dune,學習 Uniswap v2,然後用 Uniswap v3、Balancer v2 或 Curve Regular 採用上述方法。高級 SQL 函數
有了這些以太坊概念提示,讓我們來做一些高級查詢和函數。我們今天將討論以下主題:
DuneSQL 特定函數和類型
高級轉換(values/CSV、透視、窗口函數、交叉連接、unnest、累積求和、前向/後向填值)
數組函數
JSON 函數
在本指南中,所有 SQL 示例都將以 以太坊 爲中心。請記住,DuneSQL 只是 Trino SQL 的分叉。
如果你想優化你的查詢,你應該查看我們的查詢優化清單。Dune 還具有更大的引擎和物化視圖等功能,可以增強你的查詢能力。
DuneSQL 特定函數和類型
Dune 添加了一系列函數和類型,使區塊鏈數據的處理更方便、更准確(在現有 TrinoSQL 函數的基礎上)。
**首先,熟悉二進制類型。**二進制是任何帶有0x前綴的值(也稱爲字節/十六進制),它的查詢速度幾乎是varchar的2倍。你可能會遇到 Spellbook 表或上傳的數據集中某些 0x 值被輸入爲 varchar 的情況,在這種情況下,你應該在進行任何篩選或連接時使用 from_hex(varchar_col)。一些較長的二進制變量值(如函數 calldata 或事件日志數據)可以分割成若幹塊(通常是 32 字節,或使用 bytearray_substring 分割成 64 個字符),然後轉換爲數字(bytearray_to_uint256)、字符串(from_utf8)或布爾值(0x00=FALSE, 0x01=TRUE)。你可以在文檔中通過示例查看所有字節數組函數。
對於 CONCAT() 等基於字符串的函數,你需要將 varbinary 類型轉換爲 varchar 類型,這在創建區塊鏈瀏覽器鏈接時很常見。我們創建了 "get_href() "和 "get_chain_explorer_address() "等函數來簡化這一過程,你可以在此找到示例。
**其他獨特的DuneSQL類型是無符號整數和有符號整數(uint256和int256)。**這些自定義實現可以更精確地捕獲高達256字節的值,超過了64字節的大整數限制。需要注意的是,uint256 不能爲負數,而且兩者的數學運算(如除法)不兼容。在這種情況下,應該 "cast(uint256_col as double)"。稍後在除以代幣小數時,你會看到我這樣做。
如果你正在處理比特幣或 Solana 數據,它們會以 base58 編碼存儲大量值。你需要使用 frombase58(varchar) 將值轉換爲二進制,然後就可以使用上面的所有操作了。比特幣的一個好例子是識別Ordinals,Solana的一個好例子是解碼轉账數據。
高級轉換
VALUES 和 CSV 上傳
在很多情況下,你都需要使用一些自定義映射。例如,讓我們來看看 所有 ERC 標准部署的查詢。你會看到我使用了 "VALUES () as table(col1, col2, col3) "模式定義了一個 "表",我可以將其作爲 CTE 使用:

我也可以將其作爲 csv 上傳,然後將其作爲表進行查詢,但由於映射非常小,所以我在查詢中手動進行了操作。
透視(Pivoting)
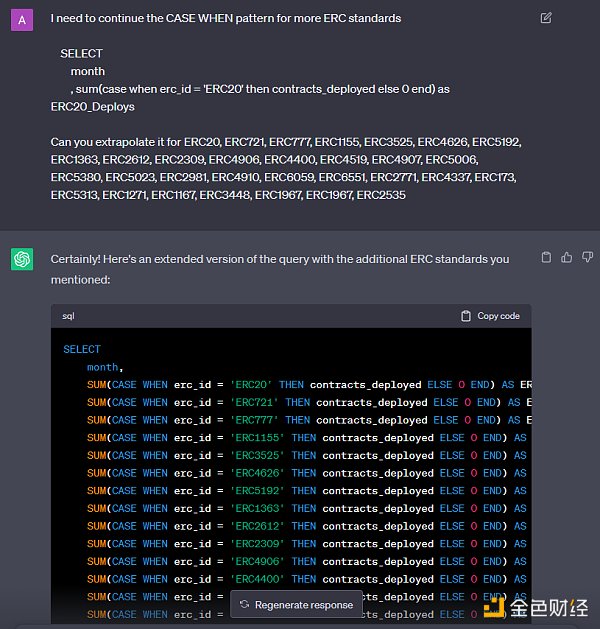
Pivoting(透視,或翻轉 )通常是指將包含一些不同類別的一列擴展爲多列(每個類別一列),反之亦然,將多列折疊爲一列。在上面的同一 ERC 查詢中,我首先在 GROUP BY 中按 erc_id 和 month 計算了合約部署的數量。這樣每個月就有大約 30 條記錄,每個 ERC 有一條記錄。我希望每個 ERC 都能成爲自己的列,以便繪制圖表,並將以太坊上线的月份數作爲行數。爲此,我對 erc_id 的每個值取SUM(case when erc_id = 'ERC20' then contracts_deployed else 0 end)。請注意,原生 DuneSQL (TrinoSQL) 還沒有動態執行此操作的透視函數。
我不想把同樣的東西敲 30 遍,所以我給 chatgpt 舉了個例子,讓他們幫我寫。一旦你弄清了基本邏輯,就應該用 chatgpt 來編寫大部分查詢(**或使用我們的Dune LLM wand feature) **!
窗口函數
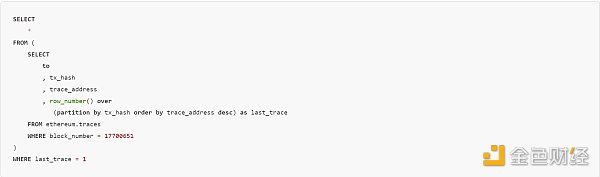
窗口函數一开始可能很難理解,因爲它要求你將一個表想象成多個不同的表。這些 "不同的表 "通過 "分區 "從主表中分割出來。讓我們從一個簡單的例子开始,找出一個塊中每個交易的最後一次調用(跟蹤)的地址。我找到了一個只有三個交易的塊:

如果你不熟悉交易跟蹤,那么它就是根交易調用之後的所有調用的集合。因此,在上面到 Uniswap 路由器的第一筆交易中,路由器將調用流動性合約,然後調用代幣合約來回發送代幣。當調用被鏈起來時,有一個[數組會遞增](https://openethereum.github.io/JSONRPC-trace-module#:~:text=每個單獨的操作.-,traceAddress 字段,-traceAddress 字段),這個數組被稱爲 trace_address。我們要獲取每個交易中最大的 trace_address 值。爲此,我們將按 tx_hash 進行分區,然後按降序爲每個 trace_address 分配一個計數器值,這樣最後的跟蹤值就是 1。SQL 代碼如下:

查詢鏈接
row_number()是一個用於窗口的函數,它只是根據行的排序從 1 开始向上計數。它將每個 tx_hash 視爲自己的表(窗口),然後應用該函數。其中一條跟蹤記錄了 257 次一級調用!
如果不使用 last_trace = 1 運行查詢,就會看到增量計數重新开始三次(每個交易一次)。很多不同的函數 都可以與窗口一起使用,包括典型的聚合函數,如 sum() 或 approx_percentile()。我們將在下面的示例中使用更多的窗口函數。
序列、Unnest、交叉連接、累積和、前向/後向填值
這五個函數是時間序列分析的基本函數。這些概念也給人們帶來了最多的麻煩,所以如果還不明白,可以通過調整不同的行來玩轉接下來的幾個子查詢。
我將使用一個查詢來展示這些概念,該查詢可捕獲某個地址持有的 ETH、ERC20 和 NFT 代幣的歷史名義余額和美元余額。
該查詢首先計算在以太坊轉账、ERC20 轉账、NFT 轉账和Gas消費中花費或收到的代幣總量--如果你還不熟悉其中的表格和邏輯,那么花點時間了解這些 CTE 是很有必要的。
一個地址可能在某些日子處於活動狀態,而在另一些日子處於非活動狀態--我們需要創建一個表來填補中間缺失的日子,以獲得准確的視圖。由於計算天數需要較長的時間,因此我將所有數據 date_trunc 爲月。在創建自首次轉入地址以來的所有 "月 "時,我們使用了unnest。
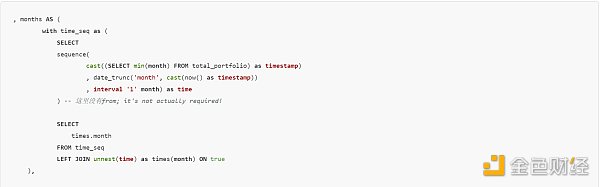
sequence 將創建一個數組,其中包含從第一個輸入到第二個輸入的值,以及第三個輸入間隔。我希望每個數組值都是一行,因此在創建的 time 列上使用了unnest,並在別名中將其重命名爲 month。我使用了 LEFT JOIN ... on true,使每個數組值只出現一次,因爲 time_seq 表只有一個值。如果 time_seq 表有兩個行值,我就會得到重復的月份。如果對更復雜的結構(如 JSON)也進行unnest(我們將在文章末尾進行unnest),這種情況就很難跟蹤了。
現在,我不僅需要跟蹤每個月的余額,還需要跟蹤該地址所持有的每個不同代幣(合約地址)的余額。這意味着我需要使用 "CROSS JOIN"(交叉連接),它可以接收任意列集,並創建它們的所有可能組合。

我同時跟蹤資產類型和資產地址,因爲有些合約可以同時鑄造 erc20 和 NFT 代幣。這裏的關鍵是 SELECT * FROM distinct_assets, months,它會獲取 "month"、"asset "和 "asset_address "這三列,並創建這樣一個表:
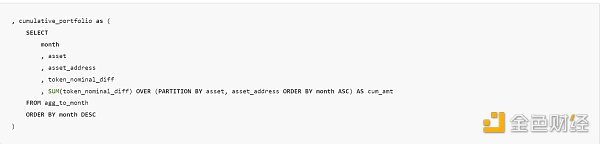
上面的子查詢還連接了所有余額變化,這意味着我可以使用差額的累計和來捕獲任何代幣在任何月份的總余額。這實際上是輕松向前填充值的一種方法。要進行累計求和,我在窗口函數中使用了 sum(),按每個資產和 asset_address 進行分區,從最早的月份开始向上求和。
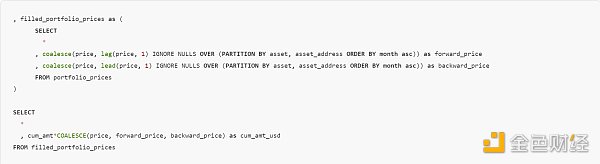
在查詢的最後一部分(加入外部 API 價格、DEX 價格和 NFT 交易價格後),我想對沒有任何交易或沒有 API 數據的日子進行前向填充和後向填充。爲此,我使用了一個創造性的 COALESCE、LEAD/LAG 和 IGNORE NULLS 窗口函數。如果某個月份還沒有價格,它就會將上一個(或下一個)非空值作爲該月份的價格。
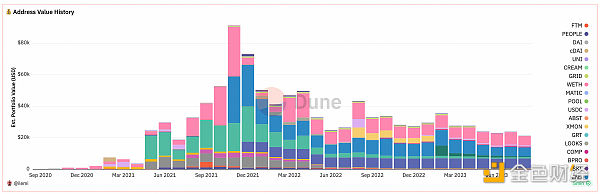
請注意,這只是估算,因爲某些封裝代幣和共享合約 NFT 集合(如 artblocks)的價格較難獲得。
該查詢 非常密集難懂。如果你想了解發生了什么,可以逐一運行每個 CTE ,並在途中進行調整!要想很好地使用這些函數,就必須善於在不運行 CTE 表的情況下在頭腦中想象出每個 CTE 表的樣子。
數組函數
數組是同一類型的值的列表,索引從 1 开始。你可以像這樣創建數組 array[1,2,3]。但更常見的是在聚合過程中創建數組。下面是一個查詢,查找最聰明的 NFT 交易者,並匯總了他們在過去 30 天內的總交易量和交易集合。

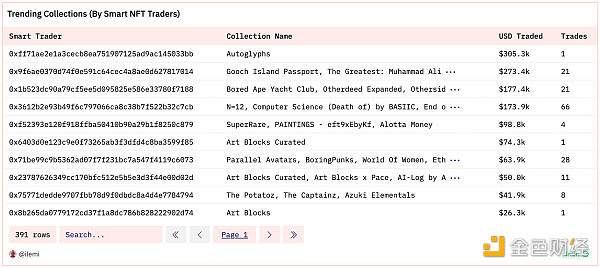
查詢鏈接
數組也可以使用很多函數。你可以使用 cardinality 來獲取數組的長度,還可以使用 contains 或 contains_sequence 來檢查數組中是否存在值。我們可以查詢所有 Uniswap 路由器的交換路徑(ERC20 代幣地址數組),其中路徑長度至少爲三個代幣,並且中間經過 WETH → USDC 或 USDC → WETH。

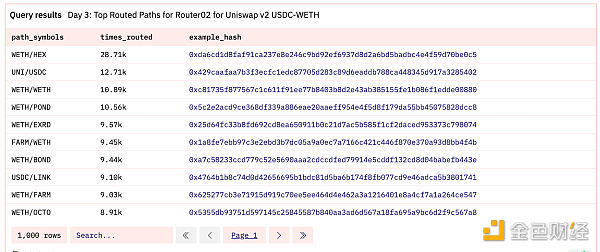
查詢鏈接
我們可以看到,WETH/HEX 兌換通過 WETH-USDC 交易對路由的次數最多。如果你對這個查詢感興趣,這裏有完整視頻講解。
有一些高級數組函數被稱爲"lambda 函數",對於在數組值之間運行更復雜的邏輯非常有用。我將在 JSON 部分介紹一個示例。如果你使用過 python/pandas,那么就和 "df.apply() " 類似。
JSON 函數
JSON 允許將不同類型的變量組合成一個嵌套結構。爲了從 JSON 中獲取值(有 許多附加參數 可用於控制路徑邏輯、缺失數據處理和錯誤錯誤,這些參數適用於所有這些):
json_query(varchar_col, 'strict $.key1.key2'):
該函數根據給定的路徑從 JSON 列中提取數據。
它將提取的數據作爲 JSON 結構保留在結果中,但類型仍然是 varchar。
json_value(varchar_col, 'strict $.key1.key2'):
它以文本、數字或數組等單個返回值中提取數據。它不會返回 JSON 結構。
如果你期望返回一個值,但它沒有返回,請考慮使用 json_query 代替。
json_extract_scalar(json_col, '$.key1.key2'):
與 json_value 相同,但當列已經是 JSON 類型時才有效。令人困惑的是,json_query 和 json_value 對 JSON 類型不起作用。
用於創建 JSON 類型列/值:
json_parse 用於將 JSON 格式的字符串轉換爲 JSON 類型。
json_object 根據指定的鍵值對構建 JSON 對象。
以太坊最著名的 JSON 類型示例是應用程序二進制接口(ABI),它定義了合約的所有函數、事件、錯誤等。下面是ERC20 代幣的 ABI的 "transferFrom() "部分:
 我創建了一個查詢,讓你可以使用 ABI 輕松查看合約中函數的所有輸入和輸出。"ethereum.contracts "的 "abi "列是一個 JSON 數組(存儲爲 "array(row())")。
我創建了一個查詢,讓你可以使用 ABI 輕松查看合約中函數的所有輸入和輸出。"ethereum.contracts "的 "abi "列是一個 JSON 數組(存儲爲 "array(row())")。
我們需要從每個值中提取輸入/輸出。爲此,我首先對abi進行 UNNEST ,然後使用json_value獲取函數名稱和狀態可變性。函數可以有多個輸入和輸出,因此我通過提取 inputs[] 數組創建了一個新的 JSON 數組。請記住,盡管 json_query 返回的是 JSON 結構,但其類型是 varchar,因此我需要先進行 json_parse 處理,然後再將其轉換爲 JSON 數組 array(row()) 。
 在又寫了幾行(我在上面省略了)進行清理並將所有輸入/輸出聚合到每個函數的單行後,我們得到了下面這個結果:
在又寫了幾行(我在上面省略了)進行清理並將所有輸入/輸出聚合到每個函數的單行後,我們得到了下面這個結果:
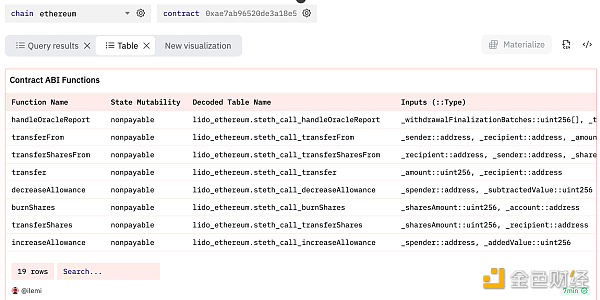
查詢鏈接
現在,還記得我前面提到的用於數組的 lambda 函數嗎?讓我們在這裏使用它們。我將從 ABI 中過濾掉 view 和 pure 函數,然後僅根據函數名創建一個數組。Lambda 函數將遍歷數組中的每個值,並應用特定邏輯。因此,我首先使用 filter 只保留滿足條件的函數,然後將過濾後的數組通過 transform 轉換,該轉換接收每個函數的 ABI json,並只返回 name。x只代表數組的值,->後面的部分是我應用到 x 的函數。我還使用了一個窗口函數,根據 created_at 列只保留最近提交的 ABI。使用 seaport 命名空間修改合約函數的完整 SQL 查詢如下:

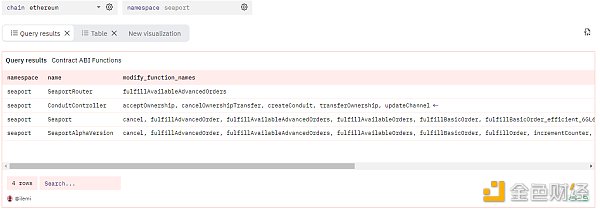
查詢鏈接
挑战: 想要真正測試一下你對本指南中每個概念的了解程度嗎?試試逆向工程我前面提到的 交易瀏覽器查詢。我在裏面用了很多小技巧。)
恭喜你成爲數據專家
慢慢消化和練習這些概念,確保對每個查詢進行分叉和把玩。僅僅閱讀並不能算作掌握!你可以利用所學的標准、類型、轉換和函數在查詢中發揮真正的創造力。
一旦這篇文章中的所有內容對你來說都是家常便飯,那么我可以輕松地說,你已經躋身以太坊上數據專家的前 1%。在此之後,你應該把更多精力放在培養自己的軟技能上,比如瀏覽社區、提出好問題和講述引人入勝的故事。或者去研究一下統計學和機器學習--它們很可能在六個月左右的時間內與 Web3 領域變得更加相關。
標題:Dune SQL 和以太坊數據分析進階指南
地址:https://www.coinsdeep.com/article/43005.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。