Amber Group:全方位解讀零知識證明
發表於 2022-09-11 10:54 作者: Odaily星球日報
1. 引言
零知識證明允許一方在不需要透露任何額外信息的前提下,向另一方進行真實性證明。因此可以用來保護隱私,在隱藏所有細節的情況下證實交易的有效性。某些特定零知識協議在驗證零知識證明上具有便利性,這很重要,例如STARK和SNARK。這些協議生成的證明較小,驗證此類證明也會快很多。這很適合資源有限的區塊鏈,並且在解決加密行業的可擴展性問題上尤爲重要。除此之外,零知識技術的其他用例還包括:
跨鏈橋——使用零知識證明(ZKP)進行狀態轉換或驗證交易,例如Alogrand ASP,Mystiko
DID(去中心化 ID)——在避免泄露詳細信息的前提下,證明某個账號或實體具有某些"特徵",例如 Sismo,First Batch
社區治理——用於匿名投票,並且在經過實踐考驗和廣泛採用後,該用例可以延展至現實社會的治理中
財務報表——實體可以在避免透露確切財務數據的前提下,證明其符合某些特定標准
雲服務的完整性——幫助雲服務供應商更好地執行任務
……
一個典型的零知識系統工作原理如下:工程師首先用領域特定語言(DSL)編寫要驗證的陳述,然後將其編譯成適合零知識的格式,比如算數環路。使用該格式生成參數後,證明系統會將這些參數與其見證的保密信息一起作爲輸入值來運行證明計算。通過相對簡單的計算,驗證者可以憑參數和證明來決定是否通過驗證。使用零知識匯總的情況下,程序或合約本身部署在layer2上,而編譯過程、參數和證明的生成將由部分layer2節點在鏈下執行,之後在以太坊主網上發布和完成驗證。
一個典型的零知識系統
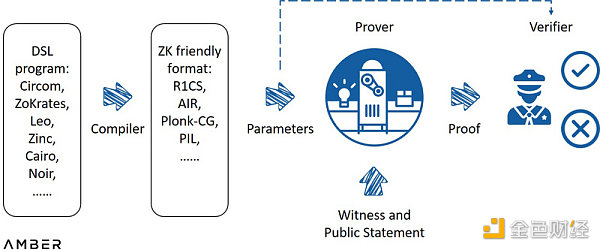
來源:ZK Whiteboard Sessions - Module One,由 Dan Boneh教授撰寫
已有多個優秀的證明系統面世,例如Marlin、Plonky2、Halo2等。不同的證明系統在生成證明的大小、驗證所需時間和是否需要可信設置等特性之間有不同的側重。經過這幾年的探索,無論陳述多么復雜,都有可能實現恆定的證明大小(幾百字節)和較短的驗證時間(幾毫秒)。
然而,證明生成的復雜性與算術環路大小幾乎成线性關系,所以難度甚至可能達到原始任務的數百倍。因爲證明者至少需要閱讀和評估環路,這就可能需要幾秒鐘到幾分鐘,甚至幾小時。算力成本高和證明時間長一直是零知識技術進步和大規模應用的主要障礙。
硬件加速可以幫助打破瓶頸。借助算法或軟件優化將多個任務分配給最適合的硬件,這將實現相輔相成。
本報告旨在幫助讀者了解市場格局、零知識技術對挖礦市場產生的影響、以及潛在機會。報告由三部分組成:
不同項目的實際用例和最新趨勢。
基於GPU、FPGA、ASIC的加速解決方案。
結語
2. 用例
列舉零知識用例將有助於說明市場是如何演變的。因爲不同類別有不同需求,所以硬件供給也牽連其中。在本節的最後,我們還將簡要比較ZKP和PoW(尤其是對於比特幣)。
2.1 新興的區塊鏈及其差異化需求
當前使用零知識技術的新興區塊鏈是硬件加速的主要需求方,大致分爲擴展解決方案和保護隱私的區塊鏈。零知識的Rollup或Volition在鏈下執行交易,並通過“數據調用”功能提交簡潔的驗證證明。保護隱私的區塊鏈使用ZKP讓用戶在避免披露交易細節的前提下,確保發起交易的有效性。
這些區塊鏈通過使用不同的證明系統來權衡證明大小、驗證時間、可信設置等特性。例如,Plonk生成的證明具有恆定的證明大小(約400字節)和驗證時間(約6毫秒),但仍需要通用的可信設置。相比之下,Stark不需要可信設置,但其證明大小(約80KB)和驗證時間(約10毫秒)欠佳,並且會隨着環路大小而增加。其他系統也各有利弊。在這些證明系統間進行權衡結果將導致計算量的“重心”發生變化。
具體來講,現在的證明系統通常可以描述爲PIOP(多項式交互預言證明)+PCS(多項式承諾方案)。前者可被視爲是證明者用來說服驗證者的約定程序,而後者使用數學方法確保該程序不會遭到破壞。這好比PCS是槍,而PIOP是子彈。項目方可以按需修改PIOP,且可以在不同PCS中進行選擇。
Paradigm的Georgios Konstantopoulos在他關於硬件加速的報告中解釋說,生成證明所需的時間主要取決於兩類計算任務:MSM(多標量乘算法)和FFT(快速傅裏葉變換)。但是,不使用固定參數,而是建立不同PIOP,並從不同PCS中進行選擇,將會帶來FFT或MSM的不同計算量。以Stark爲例,Stark使用的PCS是FRI(快速裏德-所羅門碼接近性交互預言證明),它基於裏所碼,而非KZG或IPA使用的橢圓曲线,因此在整個證明生成過程中完全不涉及MSM。我們在下表中對不同證明系統計算量進行了粗略排序,需要注意的是1)很難估計整個系統的確切計算量;2)項目方在執行時通常會按需修改系統。
不同證明系統的計算量
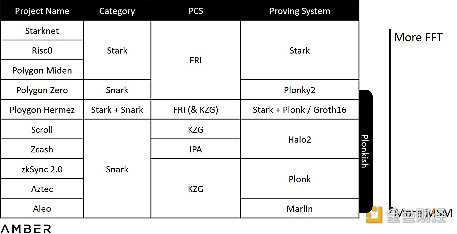
上述情況將使項目方有各自的硬件類型偏好。目前由於GPU(圖形處理器)供應量大且便於开發,GPU的使用最廣泛。此外,GPU的多核結構非常便於並行MSM計算。然而,FPGA(現場可編程門陣列)可能更擅長處理FFT,我們將在第二部分中詳述。如Starknet和Hermez等使用Stark的項目,可能更需要FPGA。
上述得出的另一個結論是,這項技術仍處於早期階段,缺乏標准化或主導的解決方案。而全面使用特定算法專用的ASIC(專用集成電路)也可能爲時過早。因此,开發人員正在探索一個中間地帶,我們稍後也會對此做進一步解釋。
2.2 趨勢與新範式
2.2.1更復雜的陳述
借鑑开篇列出的用例,我們期待零知識在加密行業和現實世界中有更多用途,並實現更復雜的證明,有些甚至可以不必遵守目前的證明系統。項目方可以不採用PIOP和PCS,而是开發最適合自己的新原語。而在如MPC(安全多方計算)的其他領域,在部分工作中採用零知識協議將大大提高其實用性。以太坊最近也爲了實現Proto-Danksharding而計劃舉辦KZG可信設置儀式,未來准備進一步實現完整版的Danksharding,以此來處理數據可用性採樣。即便是Optimistic Rollup也有可能在未來採用ZKP來提升安全性和縮短爭議處理時間。
雖然許多人可能將零知識視爲廣義加密行業中的一個獨立板塊,但我們認爲應該將零知識視爲一種解決行業多個痛點的技術。反過來看,爲了向不同系統和客戶提供服務,未來更需要硬件加速具有靈活性和通用性。
2.2.2 本地生成證明
用於保護隱私的ZKP和用於壓縮信息的ZKP在結構上有明顯差異。爲了隱藏交易細節,在證明過程中會涉及一些隨機數。用戶需要在本地生成證明,但大多數用戶沒有先進的硬件。更糟糕的是,如果大多數dapp仍然是Web APP,則需要在瀏覽器中生成證明,這將需要更長的證明時間。例如,當Manta試圖爲WASM構建高性能證明者時,他們很快意識到“與本地處理速度相比,WASM給用戶造成10-15倍的性能損失”。爲了解決這個問題,Manta選擇成爲ZPrize的贊助商和架構師,ZPrize是最大的ZKP加速競賽之一,並且Manta設置了一個WASM加速專屬賽道。提供客戶端版本是這類dapp的一個簡單解決方案,但需要下載可能會造成部分潛在用戶流失,並且客戶端也不適用於當前的擴展錢包或其他工具。
另一種解決方案是部分外包證明生成。Pratyush Mishra在第七屆零知識峰會期間介紹了這種方法。首先用戶執行部分輕量級計算,然後向數個第三方發送公开陳述和加密見證,這些第三方將接着完成剩余證明。按照這種方式,只要其中一方誠實,用戶的隱私就不會被泄露。這種方法結合了零知識協議和MPC使用的一些工具。或者,用戶也可以利用帶寬進行計算:首先生成一個大數據量證明,然後將其發送給第三方,第三方會對證明進行壓縮並將其發布到鏈上。
外包證明生成
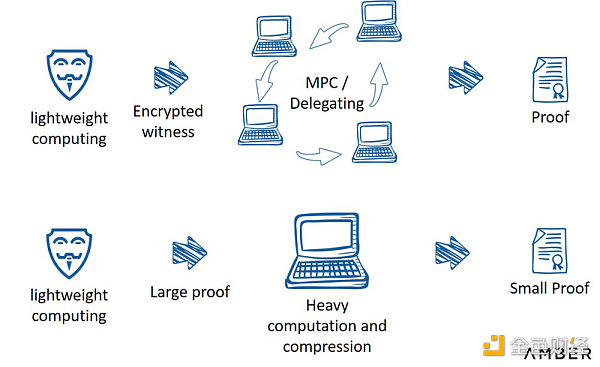
來源:第七屆零知識峰會,由Aleo的Pratyush Mishra提出
2.3 與PoW挖礦相比較
雖然人們會很自然地認爲ZKP是PoW的一種新穎形式,並將加速硬件視爲一種新型礦機,但ZKP生成在目的和市場結構上與PoW挖礦有着本質區別。
2.3.1功率競爭與效用計算
爲了賺取出塊獎勵和交易費用,比特幣礦工通過不斷迭代隨機數來尋找足夠小的哈希值,這實際上只與共識的達成相關。與此相比,ZKP生成是實現信息壓縮或隱私保護等實際效用的必要過程,而不需要對共識負責。這種區別會影響ZKP潛在的廣泛參與性和獎勵分配模式。下面我們列出了三種現有設計,來闡述礦工將如何協調ZKP生成。
Rates-are-Odds (Aleo):Aleo的經濟模型設計是最接近比特幣和其他PoW協議的。它的共識機制PoSW(簡潔工作證明)仍要求礦工找到一個有效的隨機值,但驗證過程主要以反復生成SNARK證明爲主,該證明以隨機值和狀態根的哈希值作爲輸入部分,過程直到某輪生成的證明哈希值足夠小爲止。我們將這種類似PoW的機制稱爲Rates-are-Odds模型,因爲在單位時間內可以處理的驗證數量大致決定了獲得獎勵的概率。在此模型中,礦工通過囤積大量計算機器來提高獲得獎勵的機率。
Winner-Dominates(Polygon Hermez):Polygon Hermez採用更簡單的模型。根據他們公开文檔的內容來看,兩個主要參與者是排序者和聚合者,排序者收集所有交易並將它們預處理爲新的L2批次,聚合者明確其驗證意圖並競爭生成證明。對於給定的批次,第一個提交證明的聚合者將賺取到排序者支付的費用。在不考慮地理分布、網絡狀況和驗證策略的前提下,擁有最先進的配置和硬件的聚合者可能會佔主導地位。
Party-Thresholds (Scroll):Scroll將他們的設計描述爲“Layer2證明外包”,質押一定數量加密貨幣的礦工將會被任意選擇生成證明。被選中的礦工需要在規定時間內提交證明,否則其下一個epoch的選中概率將被下調。生成錯誤的證明將會導致罰金。起初,Scroll可能會與十幾個礦工合作以提高其穩定性,甚至還會運行自有GPU。而隨着時間的推移,他們計劃分散整個過程。我們將這個實施分散的時間節點作爲參數來衡量Scroll在效率和去中心化之間的重心調整。Starkware也可能屬於此類。從長遠來看,只有擁有能夠及時完成證明的機器才能參與證明生成。
這些協調設計各有不同的側重點。我們預計Aleo將擁有最高的去中心化,Hermez將擁有最高的效率,而Scroll將擁有最低的參與門檻。但根據上述設計,零知識的硬件軍備競賽不大可能會馬上發生。
2.3.2 靜態算法與進化算法
另一個區別是比特幣是基於單一的、相對靜態的算法。比特幣的核心开發者始終嘗試遵循初始的設計與精神,以此保持網絡穩定並避免嚴重分叉。而新興的區塊鏈或項目沒有這樣的歷史遺留限制,這使他們能更靈活地調整系統和算法。
我們認爲,與結構簡單且呈現靜態的PoW市場相比,ZKP的差異性促成了一個更加分散且呈動態的市場結構。我們建議將ZKP生成視爲一種服務(一些初創公司將其命名爲ZK-as-a-Service),ZKP生成是爲達到目的而使用的手段,而非最終目的。這種新範式最終將形成新的業務或收入模式,我們將在最後一節中對此詳述。在此之前,我們先來看看多種解決方案。
3. 解決方案
CPU(中央處理器)是通用計算機中的主芯片,在主板上負責給各個組件分發指令。但是,由於CPU旨在快速處理多種任務,這反而限制了處理速度,因此在處理並發或某些特定任務時,通常使用GPU、FPGA和ASIC作爲輔助。在本節中,我們將重點介紹它們的特性、優化過程、現狀和市場。
3.1 GPU:目前最常用的硬件
GPU最初設計用來操控計算機圖形和處理圖像,但它的並行結構使其在計算機視覺、自然語言處理、超級計算以及PoW挖礦等領域成爲不錯的選擇。GPU可以加速MSM和FFT,特別是對於MSM,通過利用被稱爲“pippenger”的算法,开發GPU的過程比FPGA或ASIC要簡單得多。
在GPU上加速的理念非常簡單:將這些需要算力的任務從CPU轉移到GPU。工程師們會將這些部分重寫進CUDA或OpenCL,CUDA是一個由英偉達开發用於在英偉達GPU上進行通用計算的並行計算平台和編程模型,CUDA的競爭對手是由Apple和Khronos Group爲異構計算提供標准而打造的OpenCL,這使得用戶不再被局限於英偉達的GPU。這些代碼之後會被編譯並可直接在GPU上運行。對於更進一步的加速,拋开改進算法本身,开發人員還可以:
(1) 爲降低數據傳輸成本(尤其是CPU和GPU之間的數據傳輸),通過盡可能多使用快速存儲和少使用慢速存儲來優化內存。
(2) 爲提高硬件利用率,使硬件盡可能滿負荷工作,通過更好地平衡多處理器之間的工作、構建多核並發以及爲任務合理分配資源來優化執行配置。
簡而言之,我們要盡其所能來並行化整個工作過程。同時應盡可能避免後項依賴前項結果這樣的順序化執行過程。
通過並行化節省時間
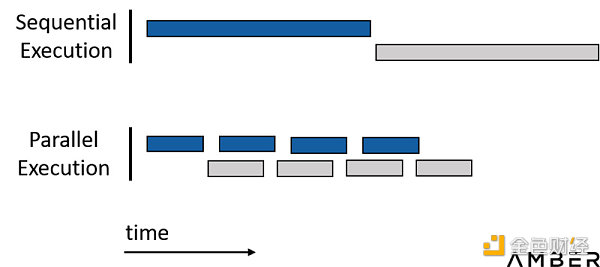
GPU加速設計流程

3.1.1 龐大的开發者群體和开發的便利性
與FPGA和ASIC不同,GPU开發不涉及硬件設計。CUDA或OpenCL也有龐大的开發者群體。开發人員能夠基於开源代碼快速建立自己的修改版本。例如,Filecoin早在2020年就發布了首個搭配GPU的網絡。Supranational最近也开源了他們的通用加速解決方案,目前這可能是同類中最好的开源解決方案。
當考慮除MSM和FFT之外的工作時,這種優勢更加明顯。證明生成的確主要由這兩項主導,但其他部分仍佔約20%(來源:Sin7Y的白皮書),因此僅加速MSM和FFT對縮短證明時間作用有限。即使將這兩項的計算時間壓縮到瞬時,所花費的總時間仍只是最初的五分之一。此外,由於這是一個新興且不斷發展的框架,因此很難預測該比率在未來將如何變化。鑑於FPGA需要重新配置,而ASIC也可能需要重新設計生產,GPU更便於加速異構計算工作。
3.1.2 過剩的GPU
英偉達主導了GPU市場。根據Jon Peddie Research的數據,2022年第一季度英偉達獨立GPU出貨量佔市場份額爲78%。盡管許多顯卡價格明顯高於MSRP(制造商建議零售價),但顯卡的供貨量還在不斷提高。2021年,GPU出貨量超過5,000萬個(價值520億美元)。從這個數字來看,這幾乎是同期FPGA銷量的8.5倍。
GPU芯片市場份額
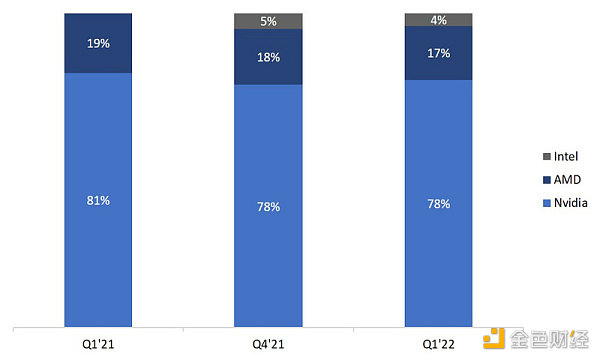
來源:Jon Peddie Research
特別是對於挖礦,我們保守估計在以太坊合並後,大約有626萬GPU將從以太坊PoW挖礦中解放出來。假設以太坊哈希率的絕大部分來自GPU,我們將以太坊當前的哈希率(890 Th/s)乘以90%,再用得到的數字(801 Th/s)除以最先進的GPU顯卡RTX 3090 Ti的挖掘能力(128 Mh/s),這樣就能得出我們保守估計的GPU數爲626萬個。由於ASIC主導比特幣挖礦,也沒有其他使用PoW的項目可以容納這么大的闲置挖礦能力,因此除了挖掘以太坊分叉或提供雲服務外,這些即將闲置的GPU轉向零知識證明服務是值得探索的選擇。
以太坊哈希率
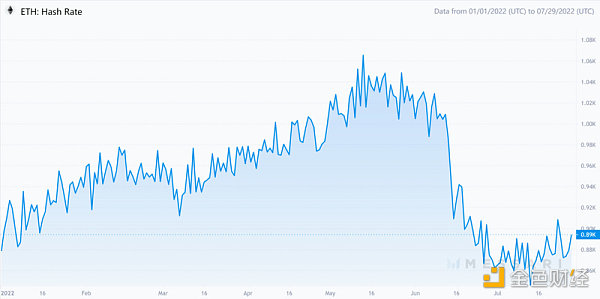
來源:Messari
3.2 FPGA:平衡成本與效率
FPGA是具有可編程結構的集成電路。因爲FPGA芯片內部的電路未經過硬蝕刻,因此設計人員可以根據特定需求對其進行多次重新編程。一方面,這有效地削減了ASIC的高額制造成本。另一方面,其硬件資源的使用比GPU更靈活,使得FPGA有進一步加速和省電的潛力。例如,盡管可以實現在GPU上優化FFT,但頻繁地打亂數據會導致GPU和CPU之間的數據傳輸量很大。然而,打亂並不是完全隨機的,通過將內在邏輯直接編寫到電路設計中,FPGA有望更快地執行任務。
要在FPGA上實現ZKP加速,仍然需要幾個步驟。首先,需要一個用C/C++編寫的特定證明系統的參考實現。然後,爲了在更高層次上描述數字邏輯電路,這個實現需要用HDL(硬件描述語言)來描述。
隨後需要通過模擬調試來顯示輸入和輸出的波形,以此查看代碼是否按預期運行。這一步是涉及實現最多的步驟。工程師不需要整個過程,而只需通過比較這兩個輸出就能識別一些微小錯誤。然後,合成器會將HDL轉換爲具有門和觸發器等元件的實際電路設計,再將設計應用到設備架構和更多模擬分析上。一旦確認電路能夠正常運行,最後將創建一個編程文件並將其加載到FPGA器件中。
FPGA設計流程
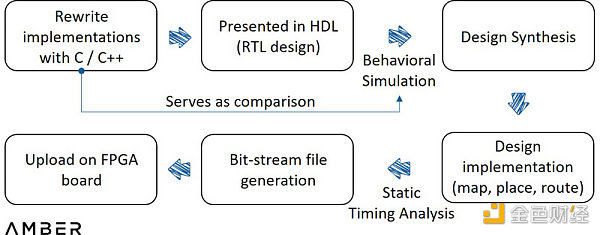
3.2.1當前的障礙和尚未完備的基礎設施
雖然可以重復利用GPU上的一些模塊優化工作,但也面臨一些新的挑战:
(1) 爲了內存安全性更高且跨平台兼容性更好,長期以來零知識的开源實現大多是用Rust編寫的,但大多數FPGA开發工具都是用硬件工程師更爲熟悉的C/C++編寫的。在實施之前,團隊可能必須重寫或編譯這些實現。
(2) 在編寫這些實現時,軟件工程師只能在範圍有限的C/C++开源庫中選擇代碼,這些庫可以通過現有的开發支持映射到硬件架構中。
(3) 除了軟件工程師和硬件工程師可以分別獨立完成的工作之外,還需要他們的密切協作來完成一些深度優化。例如,對算法的一些修改會大量節省硬件資源,同時保證其發揮與之前相同的作用,但這種優化基於對軟硬件的理解。
簡而言之,與AI或其他成熟領域不同,工程師必須從零开始學習和構建以實現ZKP加速。幸運的是,我們看到了更多進展。例如,Ingonyama在他們最近的論文中提出了PipeMSM,這是一種在FPGA或ASIC上加速MSM的方法。
3.2.2 雙頭壟斷市場
FPGA市場是典型的雙頭壟斷市場。根據Frost & Sullivan 的數據,Xilinx(2022年2月被AMD收購)和Altera(2015年12月被英特爾收購)在2019年全球FPGA市場出貨量中合計佔比約85%。想要盡早使用最先進的FPGA可能需要與英特爾或AMD建立密切關系。此外,零知識作爲新興領域已經引起了行業巨頭的注意。AMD是ZPrize的技術提供商之一。
FPGA市場是典型的雙頭壟斷市場
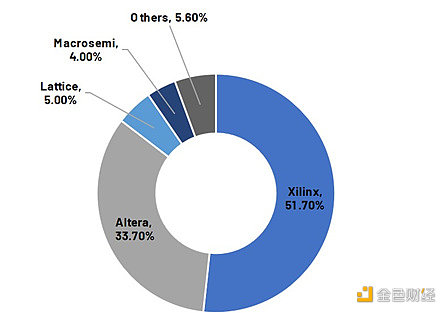
來源:Frost & Sullivan
工程師們已經意識到,單個FPGA無法爲復雜的ZKP生成提供足夠的硬件資源,因此必須同時使用多卡進行驗證。即使有完備的設計,AWS及其他供應商提供的現有標准FPGA雲服務並不理想。此外,提供加速解決方案的初創公司通常規模太小,無法讓AWS或其他公司托管他們的定制化硬件,而且他們也沒有足夠的資源來運行自己的服務器。與大型礦工合作或與Web3原生雲服務提供商合作可能是更好的選擇。然而,考慮到挖礦公司的內部工程師也可能將开發加速解決方案,這種合作關系可能會很微妙。
3.3 ASIC:終極武器
ASIC是爲特定用途專門定制的集成電路(IC)芯片。通常,工程師仍會使用HDL來描述ASIC的邏輯,這種方式類似於使用FPGA,但最終電路會永久地繪制到硅片中,而FPGA中的電路是通過連接數千個可配置模塊而制成的。不同於從英偉達、英特爾或AMD採購硬件,公司必須設法自己完成從電路設計到制造和測試的整個過程。ASIC將僅限於某些特定功能,但相反在資源分配和電路設計方面這賦予設計人員最大程度的自由度,因此ASIC在性能和能耗效率方面擁有巨大潛力。設計人員可以在空間、功率和功能上消除浪費,只需根據預期應用來設計確切數量的門,或調整不同模塊的大小。
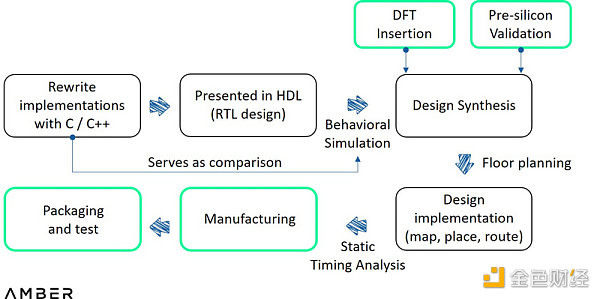
在設計流程方面,與FPGA相比,ASIC需要在HDL的編寫和整合這兩步之間加入流片前驗證(以及DFT),並且實施前需要布圖規劃。前者是工程師在虛擬環境中使用復雜模擬工具測試設計,後者用於確定芯片中模塊的尺寸、形狀和位置。設計實現後,所有文件都會被送到台積電或三星等代工廠進行測試流片。如果測試成功,則會將原型送去組裝和檢測。
ASIC設計流程
3.3.1 零知識領域相對通用的ASIC
ASIC遭到的一個普遍批評是,一旦算法改變,以前的芯片就完全沒用了,但不一定如此。
巧合的是,與我們交流過的所有計劃开發ASIC的公司都沒有孤注一擲於特定的證明系統或項目。相反他們更喜歡在ASIC上开發一些可編程模塊,以便通過這些模塊應對不同的證明系統,並且只將MSM和FFT任務分配給ASIC。這對於特定項目的特定芯片來說不是最理想的,但是在短期內比起用於特定任務的設計,犧牲性能來獲得更好的通用性可能是更優的選擇。
3.3.1 昂貴但非經常性的成本投入
不僅ASIC的設計過程比FPGA復雜得多,而且制造過程也會消耗更多的時間和金錢。初創公司可以直接聯系代工廠進行流片或通過分銷商。到真正能夠开始執行可能需要等待大約三個月或更長時間。流片的主要成本來自於掩模版和晶圓。掩模版用於在晶圓上形成圖形,晶圓是一片薄硅片。初創公司通常選擇MPW(多項目晶圓),可以與其他項目方共同分擔掩模版和晶圓的制造成本。但是,取決於他們選擇的工藝和芯片數量,保守估計流片成本仍將高達數百萬美元。流片以及組裝和測試還需要幾個月的時間。如果可行,才終於能夠开始准備量產。但是,如果測試出現任何問題,調試和故障分析又將花費難以估計的時間,並且需要再次流片。從最初的設計到量產需要幾千萬的資金,還需要大約18個月的時間。得以慰藉的是,上述成本的很大一部分屬於非經常性成本。此外,ASIC擁有高性能且能夠節省能源和空間,這都是很重要的,並且價格可能相對較低。
4.結語
下面我們對不同硬件解決方案進行了一般性評估。
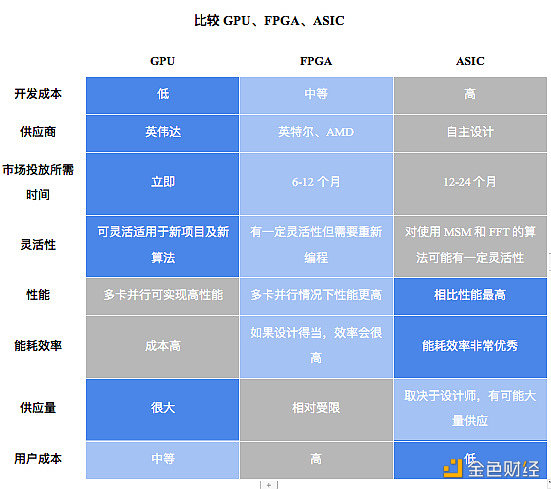
來源:Amber
爲了更直觀地了解可用商業模式,我們在如下圖表中展示了所有潛在的市場參與者。由於參與者之間可能存在交叉關系或者復雜情況,因此我們僅按功能對他們進行分類。
硬件加速的功能層
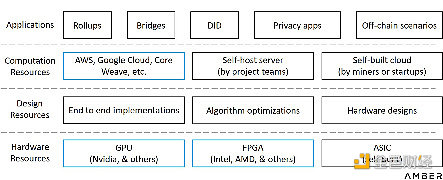
除了开發GPU或FPGA芯片外,初創公司還可以從上述任何功能層進入零知識領域。可以選擇從零开始設計和制造ASIC,並將芯片封裝成專用設備賣給礦工,或者可以將裸芯片賣給下遊供應商組裝。初創公司還可以選擇自建服務器,參與證明生成或提供雲服務。或者,也可以選擇成爲咨詢公司,提供設計解決方案,但不參與實際操作。如果公司擁有強大的合作夥伴關系或足以覆蓋整個價值鏈的資源,那么還可以爲零知識應用程序提供從硬件資源到定制化系統設計的全棧解決方案。
零知識尚未實現大規模應用,構建加速解決方案也將是一個漫長的過程。我們拭目以待未來的轉折點。對於構建者和投資者來說,關鍵問題是這個轉折點何時到來。
致謝
特別感謝Weikeng Chen(DZK)、Ye Zhang(Scroll)、Kelly(Supranational)和Omer(Ingonyama)幫助我們理解所有技術細節。還要感謝Kai(ZKMatrix)、Slobodan(Ponos)、Elias和Chris(Inaccel)、Heqing Hong(Accseal)和許多其他人對本研究提供見解。
來源:Amber Group、星球日報
標題:Amber Group:全方位解讀零知識證明
地址:https://www.coinsdeep.com/article/6659.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。