重塑計算界限:去中心化算力的現狀與展望
發表於 2023-11-28 09:09 作者: 金色精選
 免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
重塑計算界限:去中心化算力的現狀與展望

 金色精選
金色官方
剛剛
金色精選
金色官方
剛剛
 關注
關注
來源:Future3 Campus
伴隨 AI 等領域的發展,許多行業會從底層邏輯上實現巨大變革,算力會上升到更重要的地位,與之關聯的各個方面也都會引起行業的廣泛探索,去中心化算力網絡有其自身優勢,可答復降低中心化風險,同時也能作爲中心化算力的一種補足。
需求中的算力
自2009年《阿凡達》上映,以無與倫比的真實畫面掀开3D電影第一役,Weta Digital 作爲其背後的巨大功臣貢獻了整部電影的視效渲染工作。在它新西蘭的佔地10000平方英尺的服務器農場裏,它的計算機群每天處理高達140萬個任務,每秒處理8GB的數據,即使這樣也接連持續運行了超過1個月,才完成所有的渲染工作。
大規模的機器調用和成本投入,《阿凡達》成就電影史上的卓著功勳。
同年1月3日,中本聰在芬蘭赫爾辛基的一個小型服務器上挖出了比特幣的創世區塊,並獲得了50btc的出塊獎勵。自加密貨幣誕生第一天起,算力一直在行業扮演非常重要的角色。
The longest chain not only serves as proof of the sequence of events witnessed, but proof that it came from the largest pool of CPU power.
—— Bitcoin Whitepaper
在PoW共識機制的大背景下,算力的付出爲鏈的安全性提供保障。同時,持續走高的Hashrate 也能佐證礦工的算力上的持續投入和積極的收入預期。行業對算力的真實需求,也極大推動了芯片廠商的發展。礦機芯片經歷了CPU、GPU、FPGA、ASIC等發展階段。目前,比特幣礦機通常是基於ASIC(Application Specific Ingrated Circuit)技術的芯片能高效地執行特定的算法,如SHA-256。比特幣帶來的巨大經濟效益,也拉動着相關挖礦的算力需求一並走高,但過於專用化的設備和集群效應,使得本身參與者發生虹吸效應,無論是礦工或礦機制造商,都呈現資本密集型的集中發展趨勢。
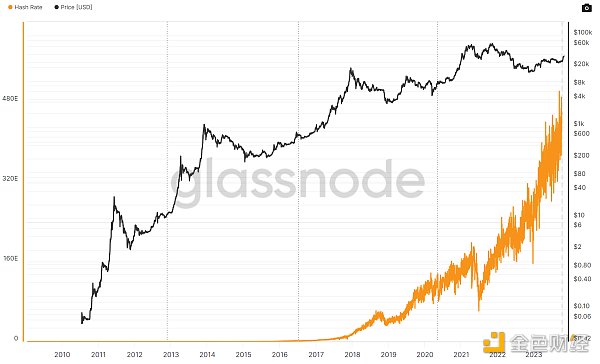
而隨着以太坊的智能合約問世,隨着它的可編程性、可組合性等特點,形成了廣泛的應用,特別是在 DeFi 領域的運用,使得ETH的價格一路看漲,而還處於 PoW 共識階段的以太坊其挖礦難度也一路走高。礦工對以太坊礦機的算力要求也與日俱增,但以太坊與比特幣使用ASIC芯片不同,則需要使用圖形處理器(GPU)來進行挖礦計算,如Nvidia RTX系列等。這樣它更適合通用計算硬件來參與,這甚至一度引發了,市場對於GPU的爭搶而導致市面上高端的顯卡一度斷貨的局面。
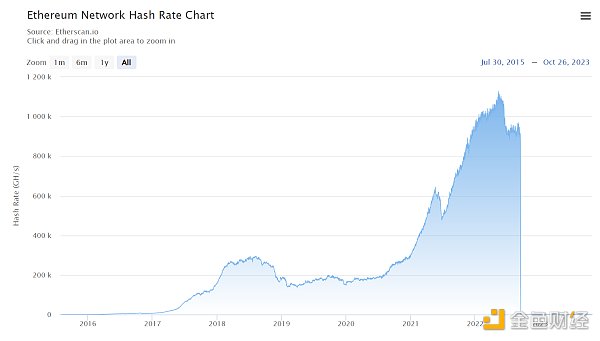
而當時間來到2022年11月30日,由 OpenAI 研發的 ChatGPT 同樣是展示了 AI 領域劃時代的意義,用戶驚嘆於 ChatGPT 帶來的全新體驗,能如同真人一般,基於上下文完成用戶提出的各種要求。而在今年9月推出的新版本中,加入了語音、圖像等多模態特徵的生成式AI又將用戶體驗帶到了更新的階段。
但與之對應的是GPT4有超過萬億級的參數參與模型預訓練以及後續微調。這是 AI 領域對算力需求最大的兩個部分。在預訓練階段,通過學習大量的文本來掌握語言模式、語法和關聯上下文。使其能夠理解語言規律,從而根據輸入生成連貫且上下文相關的文本。預訓練之後,再對GPT4進行微調,以便於更好地適應特定類型的內容或風格,提升特定需求場景的性能和專業化。
由於 GPT 採用的 Transformer 架構,引入自注意力機制(Self-attention),這種機制使得模型能在處理輸入的序列時,同時關注序列中不同部分之間的關系,因而對算力需求急劇增長,特別是在處理長序列是需要大量並行計算和存儲大量注意力分數,因而也需要大量的內存和高速的數據傳輸能力。目前主流的同架構LLM對於高性能GPU的需求巨大,這也表明AI大模型領域投入成本巨大。根據相關 SemiAnalysis 的推測估計GPT4一次模型訓練成本高達6300萬美金。而爲實現良好的交互體驗,GPT4 在日常運營中亦需要投入大量的算力來維持其日常運營。
算力硬件分類
這裏我們要來理解一下目前主要的算力硬件類型,CPU、GPU、FPGA、ASIC 分別能處理怎樣算力需求場景。
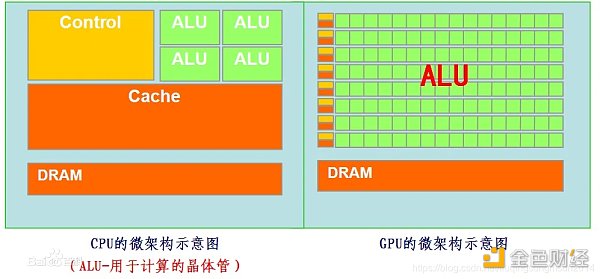
• 從CPU和GPU的架構示意圖上,GPU包含更多核心,它們使得GPU可同時處理多個計算任務,並行計算的處理能力更強,適用於處理大量計算任務,因此在機器學習和深度學習領域得到了廣泛的應用。而CPU的核心數量較少,適合處理更集中地處理單個復雜計算或序列任務,但在處理並行計算任務時不如GPU高效。在渲染任務和神經網絡計算任務中,通常需要處理大量重復計算和並行計算,因此GPU比CPU在這個方面會更高效且適用。
• FPGA(Field Programmable Gate Array)現場可編程邏輯門陣列,是作爲專用集成電路(ASIC)領域中的一種半定制電路。由大量小型處理單元組成的陣列,FPGA可以理解爲可編程的數字邏輯電路集成芯片。目前的運用主要集中在硬件加速,其他任務仍然在CPU上完成,讓FPGA和CPU協同工作。
• ASIC(Application Specific Integrated Circuit)專用集成電路,是指應特定用戶要求和特定電子系統的需要而設計的集成電路。ASIC在批量生產時與通用集成電路相比具有體積更小、功耗更低、可靠性提高、性能提高、保密性增強、成本降低等優點。因而在比特幣挖礦的固有場景下,只需要執行特定的計算任務,ASIC則是最契合的。Google 也推出了針對機器學習專門設計的 TPU(Tensor Processing Unit)作爲ASIC的一種,但目前主要通過Google Cloud提供算力租用服務。
• ASIC 和 FPGA 相比,ASIC 是專用集成電路,一旦設計完成後集成電路即固定。而FPGA是在陣列內集成大量數字電路基本門電路和存儲器,开發人員可以通過燒寫FPGA配置來定義電路,並且這種燒寫是可更換的。但就當下的AI領域的更新速度,定制化或半定制化的芯片,無法及時通過調整重新配置來執行不同的任務或適應新算法。因而,GPU 的普遍的適應性和靈活性,使其在 AI 領域大放異彩。各大 GPU 廠商就 AI 領域也對 GPU 在 AI 領域的適配做了相關優化。以 Nvidia 爲例,推出了專爲深度學習設計的 Tesla 系列和 Ampere 架構 GPU,這些硬件包含針對機器學習和深度學習計算優化的硬件單元(Tensor Cores),這使得GPU能夠以更高的效率和更低的能耗執行神經網絡的前向和反向傳播。此外也提供了廣泛的工具和庫來支持AI开發,如 CUDA(Compute Unified Device Architecture)來幫助开發人員利用GPU進行通用並行計算。
去中心化算力
去中心化算力是指通過分布式計算資源提供處理能力的方式。這種去中心化的方法通常結合區塊鏈技術或類似的分布式账本技術,將闲置的計算資源匯集並分發給需要的用戶,以實現資源共享、交易和管理。
產生背景
• 強勁的算力硬件需求。創作者經濟的繁榮,使得數字媒體處理方向進入全民創作的時代,激增的視效渲染需求,出現專門渲染外包工作室、雲渲染平台等形式,但這樣方式也需要本身投入大量的資金用於前期算力硬件採購。
• 算力硬件來源單一。AI 領域發展更加劇了算力硬件的需求,全球以 Nvidia 爲龍頭的 GPU 制造企業在這場AI算力競賽中,賺得盆滿鉢滿。其供貨能力甚至成爲能掣肘某一行業發展的關鍵要素,Nvidia的市值也於今年首次突破一萬億美元。
• 算力提供仍主要依賴中心化雲平台。而目前真正受益於高性能計算需求激增的是以 AWS 爲代表的中心化雲廠商,它們推出了 GPU 雲算力服務,以目前AWS p4d.24xlarge 爲例,租用一台這樣的專精於 ML 方向的 HPC 服務器,包含8塊 Nvidia A100 40GB GPUs,每小時花費在 32.8 美元,其毛利率據估計可達61%。這也使得其他雲巨頭紛紛競相參與,囤積硬件以其在行業發展初期盡可能佔據有利。
• 政治、人爲幹預等因素導致行業發展不平衡。不平衡我們不難看出GPU的所有權和集中度更向資金和技術充裕組織和國家傾斜,且與高性能計算集群呈現依仗關系。這使得以美國爲代表的芯片半導體制造強國,也在對AI芯片出口方面實施更爲嚴苛的限制, 以削弱其他國家在通用人工智能領域的研究能力。
• 算力資源分配過於集中。 AI 領域的發展主動權掌握在少數巨型公司手中,目前以 OpenAI 爲代表的巨頭,有微軟的加持,背後是微軟Azure 提供的豐富算力資源,這使得 OpenAI 每次新產品的發布,都是對當下 AI 行業的重塑和整合,讓其余團隊在大模型領域難以望其項背。
那么在面對高昂的硬件成本、地域限制、產業發展不均衡的情況,是否有其他解決方案?
去中心化算力平台則應運而生,平台的目的是創建一個开放、透明且自我調節的市場來更有效地利用全球計算資源。
適應性分析
1. 去中心化算力供給側
目前高昂的硬件價格和供給側的人爲控制,都給去中心化算力網絡的建設提供了土壤。
• 從去中心化算力的組成方式來看,多樣的算力提供方小到個人PC、小型物聯網設備大到數據中心、IDC等,大量累積的算力可提供更靈活和可擴展的計算解決方案,從而幫助更多的AI开發者和組織更有效地利用有限的資源。都可以通過個人或組織的闲置算力,來實現去中心化算力共享,但這些的算力的可用性、穩定性,受本身用戶的使用限制或分享上限的限制。
• 有可能的潛在優質算力來源,則是以太坊轉 PoS 後,直接由相關礦場轉型提供的算力資源。以美國領先的 GPU 集成式算力提供商 Coreweave 爲例,前身是北美以太坊最大的礦場,基於已構建的完備基礎設施。此外,退役的以太坊礦機,其中也包含了大量的闲置 GPU,據悉此前以太坊挖礦時代巔峰在網工作的 GPU 約2700萬張,盤活這些 GPU 也能進一步成爲去中心化算力網絡重要的算力來源。
2. 去中心化算力需求側
• 從技術實現來看,去中心化算力資源在圖形渲染類,視頻轉碼類,這種計算復雜程度不高的任務,結合區塊鏈技術和web3的經濟體系能在確保信息數據安全傳遞情況下,爲網絡參與者帶來了切實的收益激勵,積累了有效的商業模式和客群。而 AI 領域則涉及大量的並行計算,節點間的通信、同步等環節,對網絡環境等方面有非常高的要求,因而目前應用也都集中於微調、推理、AIGC 等更偏應用層。
• 從商業邏輯來看,單純算力买賣的市場是缺乏想象力的,行業只能卷供應鏈、定價策略,但這些又恰好是中心化雲服務的優勢。因而,市場上限較低也缺乏更多想象空間,所以也能看到原本做單純圖形渲染的網絡在尋求 AI 轉型,如 Render Network 與2023 Q1 也推出了原生集成Stability AI 工具集,用戶可以的該項功能引入Stable Diffusion作業,業務也不再局限於渲染作業而向 AI 領域擴展。
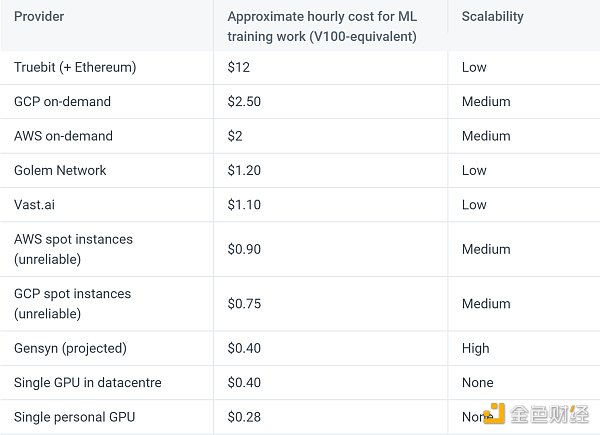
• 從主要客群來看,很顯然大B端客戶會更傾向於中心化集成式雲服務,他們通常有充足的預算,他們通常是從事底層大模型的开發,需要更高效的算力聚合形式;因而,去中心化算力更多的是服務於中小型开發團隊或個人,從事多是模型微調,或應用層开發,對算力的提供形式沒有太高的要求。他們對價格更敏感,去中心化算力的能從根本上減輕初始成本的投入,因而整體的使用成本也更低,以 Gensyn 此前測算的成本來看,將算力換算成V100 提供的等值算力,Gensyn 價格僅爲0.4美元每小時,相比AWS 同類型的算力需要2美元每小時,能下降80%。雖然這部分生意並不在目前行業中佔开銷大頭,但伴隨 AI 類應用的使用場景持續延展,未來的市場規模不容小覷。
• 從提供的服務來看,可以發現目前的項目更像是去中心化雲平台的概念,提供的是一整套從开發、部署、上线、分發、交易全流程的管理,這樣的好處在於吸引开發者,可以利用相關工具組件來簡化开發部署,提升效率;同時能吸引用戶來平台使用這些完整的應用產品,形成基於自身算力網絡的生態護城河。但這同時也對項目運營提出了更高的要求。如何吸引優秀开發者和用戶並實現留存顯得尤爲重要。
不同領域的應用
1. 數字媒體處理
Render Network 一個基於區塊鏈的全球渲染平台,其目標是爲創作者數字創意提供幫助。它允許創作者按需將 GPU 渲染工作擴展到全球 GPU 節點,提供了以一種更爲高速且便宜的渲染工作能力,在創作者確認過渲染結果後,再由區塊鏈網絡向節點發送代幣獎勵。相比傳統的視覺效果實現方法,在本地建立渲染基礎設施或在購置的雲服務中增加相應的GPU开支,這都需要高昂的前期投入。
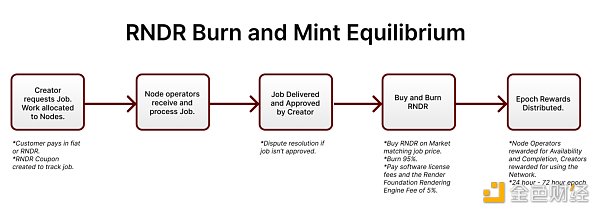
自2017年創立以來,Render Network 用戶在網絡上渲染了超過1600萬幀和近50萬個場景。從Render Network 2023 Q2 發布數據也能表明,渲染幀數作業和活躍節點數都呈增長的趨勢。此外,Render Network 與2023 Q1 也推出了原生集成Stability AI 工具集,用戶可以的該項功能引入Stable Diffusion作業,業務也不再局限於渲染作業而向AI領域擴展。
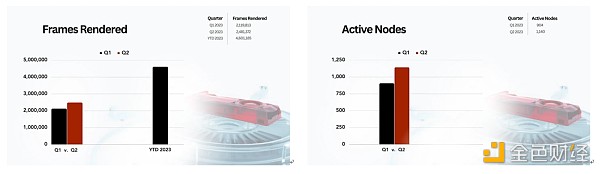
Livepeer 則是通過網絡參與者貢獻自己的GPU算力和帶寬,爲創作者提供實時視頻轉碼服務。廣播者可以通過將視頻發送至Livepeer,完成各類視頻轉碼,並向各類端側用戶分發,進而實現視頻內容的傳播。同時,可以便捷地通過法幣形式支付,獲得視頻轉碼、傳輸、存儲等服務。
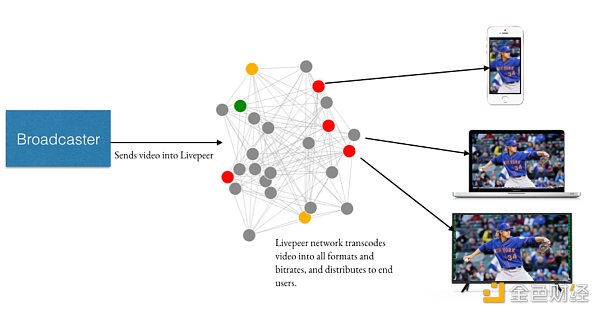
在Livepeer 網絡中,任何人都允許貢獻個人計算機資源(CPU、GPU 和帶寬)以進行轉碼和分發視頻來賺取費用。 原生代幣(LPT)則代表了網絡參與者在網絡中的權益,通過質押代幣的數量,決定節點在網絡中的權重,從而影響其獲得轉碼任務的機會。同時,LPT也起到了引導節點安全、可靠、快速地完成分派的任務。
2. AI領域的擴展
在目前AI領域的生態系統中,主要參與者大致可以劃分成:
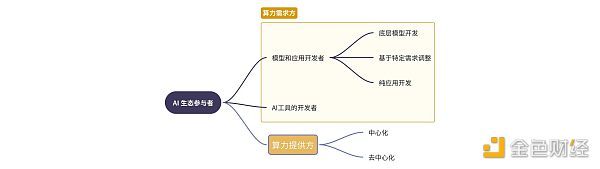
從需求方入手,在產業的不同階段,對算力的訴求是有明顯區別的。以底層模型开發爲例,在預訓練環節爲確保訓練結果的有效對並行計算、存儲、通信等方面要求都非常高,這就需要通過大型的算力集群來完成相關的任務。當下主要算力供給主要還是依賴自建機房、中心化的雲服務平台來集中提供。而在後續模型微調、實時推理和應用开發等環節則對並行計算、節點間通信的要求沒有那么高,這恰恰是去中心化算力能一展拳腳的部分。
縱觀此前已頗具的聲量的項目, Akash Nework 在去中心化算力方向做了一些嘗試:
Akash Network 結合不同的技術組件,讓用戶可以在去中心化的雲環境中高效、靈活地部署和管理應用程序。用戶可以利用 Docker 容器技術打包應用,然後通過 Kubernetes 在 Akash 提供的雲資源上通過 CloudMOS 進行部署和擴展。Akash 採用“反向拍賣”的方式,這使得價格比傳統雲服務更低。
Akash Network 在今年8月也發布將推出了主網第6次升級,將對 GPU 的支持納入其雲服務中,未來向更多 AI 團隊提供算力供給。
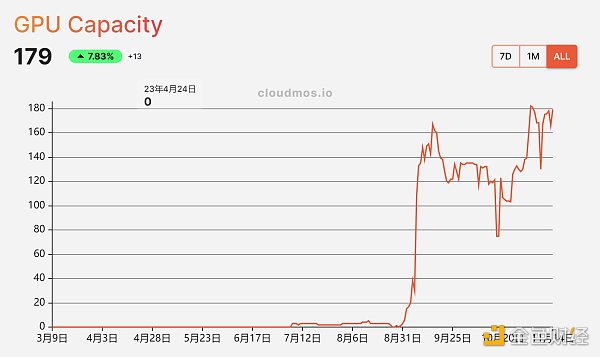
Gensyn.ai,今年頗受行業矚目的項目由 a16z 領投完成了4300萬美元A輪融資,就目前公布項目公布的文檔來看, 該項目是一個主網基於波卡網絡的 L1 PoS 協議,聚焦於深度學習,它旨在通過創建一個全球性的超級計算集群網絡來推動機器學習的邊界。這個網絡連接了從擁有算力富余的數據中心到潛在可貢獻個人 GPU 的 PC,定制的 ASIC 和 SoC 等多種設備。
爲解決的目前去中心化算力中存在的一些問題,Gensyn 借鑑了學術界的一些理論研究新成果:
1. 採用概率學習證明,即使用基於梯度的優化過程的元數據來構建相關任務執行的證明,來加快驗證過程;
2. 圖形基准協議(Graph-based Pinpoint Protocol),GPP作爲一個橋梁,連接了DNN(Deep Neural Network)的離线執行與區塊鏈上的智能合約框架,解決了跨硬件設備間容易發生的不一致性,並確保了驗證的一貫性。
3. 與 Truebit 類似的激勵方式,通過質押和懲罰相結合的方式,建立一個能讓經濟理性參與者能誠實地執行分派的任務。該機制採用了密碼學和博弈論方法。這個驗證系統對於維持大型模型訓練計算的完整性和可靠性。
但值得注意的是以上內容更多的是解決任務完成驗證層面,而非在項目文檔中作爲主要亮點講述的關於去中心化算力來實現模型訓練方面的功能,特別是關於並行計算和分布式硬件間通信、同步等問題的優化。當前受網絡延遲(Latency)和帶寬(Bandwidth)的影響,頻繁的節點間通信會使得迭代時間和通信成本都發生增長,這不僅不會帶來實際的優化,相反會降低訓練效率。Gensyn 在模型訓練中處理節點通信和並行計算的方法可能涉及復雜的協調協議,以管理計算的分布式性質。然而,如果沒有更詳細的技術信息或對他們具體方法的更深入了解,Gensyn通過其網絡實現大型模型訓練的確切機制需要等項目上线才能真正揭曉。
我們還關注到 Edge Matrix Computing (EMC) protocol 它通過區塊鏈技術將算力運用至 AI、渲染、科研、AI電商接入等類型的場景,通過彈性計算把任務分發到不同的算力節點。這種方法不僅提高了算力的使用效率,還確保了數據傳輸的安全性。同時,它提供了一個算力市場,用戶可以訪問和交換計算資源。方便开發者部署,更快地觸達用戶。結合 Web3 的經濟形式,也能使算力提供方在根據用戶的實際使用情況獲取真實收益和協議方補貼,AI开發者也獲得更低的推理和渲染成本。以下是其主要組成部分和功能的概述:
預期還將推出了基於 GPU 的 RWA 類產品,此項的關鍵在於將原本在機房固定住的硬件盤活,以 RWA 的形式分割流通,獲得額外的資金流動性,高質量 GPU 能作爲 RWA 底層資產的原因在於,算力可以算得上 AI 領域的硬通貨,目前有明顯的供需矛盾,且該矛盾並不能在短期內解決,因而 GPU 的價格相對比較穩定。
此外,通過部署 IDC 機房實現算力集群也是 EMC protocol 會重點布局的部分,這不僅能讓 GPU 在統一環境下的運轉,更高效地處理相關大型算力消耗的任務,如模型的預訓練,由此來匹配專業用戶的需求。同時,IDC 機房也能集中托管和運行大量的 GPU,確保同類型高質量硬件的技術規格,方便將其打包作爲 RWA 產品推向市場,开啓DeFi 新思路。
近年學界在邊緣計算領域也有新的技術理論發展和應用實踐。邊緣計算作爲雲計算的一種補充和優化,一部分的人工智能正在加快速度從雲端走向邊緣,進入到越來越小的物聯網設備中。而這些物聯網設備往往體積很小,爲此輕量機器學習受到青睞,以滿足功耗、延時以及精度等問題。

Network3 是通過構建了一個專門的AI Layer2,通過AI 模型算法優化和壓縮,聯邦學習,邊緣計算和隱私計算,爲全球範圍內的AI开發者提供服務,幫助他們快速、便捷、高效地訓練或者驗證模型。它通過利用大量智能物聯網硬件設備,可聚焦小模型,來做相應的算力供給,且通過構建TEE(Trusted Execution Environment)能讓用戶僅通過上傳模型梯度,來完成相關訓練,確保用戶相關數據隱私安全。
綜上
• 伴隨 AI 等領域的發展,許多行業會從底層邏輯上實現巨大變革,算力會上升到更重要的地位,與之關聯的各個方面也都會引起行業的廣泛探索,去中心化算力網絡有其自身優勢,可答復降低中心化風險,同時也能作爲中心化算力的一種補足。
• 且本身 AI 領域的團隊也處於一個分岔口上,是否利用已訓練好的大模型構建自身產品,還是參與到訓練各自地域內的大模型,這樣的選擇也多是辯證的。因而去中心化算力能滿足不同的業務需求,這樣的發展趨勢是喜聞樂見的,且伴隨技術的更新和算法的迭代,勢必在關鍵領域也會有所突破。
• 至不懼,而徐徐圖之。
 打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 金色精選 > 重塑計算界限:去中心化算力的現狀與展望
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 金色精選 > 重塑計算界限:去中心化算力的現狀與展望
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
標題:重塑計算界限:去中心化算力的現狀與展望
地址:https://www.coinsdeep.com/article/69403.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。