Sora橫空出世 會顛覆哪些行業?
發表於 2024-02-20 08:50 作者: 澤平宏觀
來源:澤平宏觀
2月16日,OpenAI發布視頻生成模型Sora,極大拓展AI在視頻內容生成方面能力。Sora在關鍵指標上大幅領先之前的一些視頻生成類模型,用它生成視頻,會發現其對物理世界的空間模擬能力甚至達到了逼近真實的水平。
Sora爲什么可以堪稱是AI界的新裏程碑?它是如何突破AIGC即AI內容創作上限的?客觀來看,當前版本的Sora還有沒有什么局限性和不足?
Sora等視頻生成類模型,未來更新迭代的方向是什么?它的出現會顛覆哪些行業?對我們每個人產生何種影響?它的背後又有什么新產業機遇?
1、Sora是怎么實現的?爲什么是AI界的新裏程碑?
Sora之所以是AI裏程碑,是因爲它再一次突破了AIGC用AI驅動內容創作的上限。此前大家已經开始使用Chatgpt等文本類輔助內容創作,輔助插圖和畫面生成,用虛擬人做短視頻。而Sora是視頻生成類大模型,通過輸入文本或圖片可生成、連接、擴展等多種方式編輯視頻,屬於多模態大模型範疇,該類模型是在GPT這類語言類大模型上進一步延伸、拓展。Sora通過一種類似於GPT-4對文本令牌進行操作的方式來處理視頻“補丁”。該模型的關鍵創新在於將視頻幀視爲補丁序列,類似於語言模型中的單詞令牌,使其能夠有效地管理各種視頻。這種方法與文本條件生成相結合,使Sora能夠根據文本提示生成上下文相關且視覺上連貫的視頻。
具體原理上,Sora主要通過三個步驟實現視頻訓練。首先是視頻壓縮網絡,將視頻或圖片降維成一個緊湊、高效的形式。其次是時空補丁提取,將視圖信息分解成一個個更小的單元,每個單元都含有視圖中一部分的空間和時間信息,便於Sora在之後的步驟中能進行針對性處理。最後是視頻生成,輸入文本或圖片進行解碼加碼,由Transformer模型(即ChatGPT基礎轉換器)決定如何將這些單元轉換或組合,從而將文本和圖片提示中的內容形成完整的視頻。
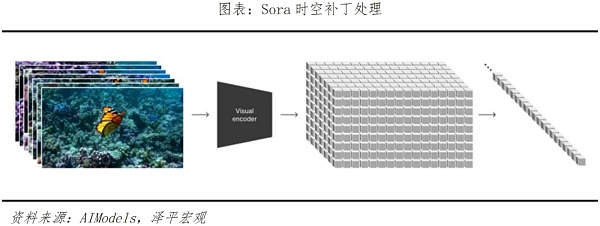
Sora在視頻生成模型最關鍵的兩項指標——時長和分辨率上大幅超越先前模型,並且具備較強的文本理解深度和細節生成能力,可以說是AI界的又一裏程碑級的產品。Sora發布前,主要模型如Pika1.0、Emu Video、Gen-2可生成時長分別爲3~7秒、4秒、4~16秒;而Sora可生成時長高達60秒,能實現1080p分辨率,且Sora不僅能基於文本提示生成視頻,也具備視頻編輯和擴展能力。Sora對文本的深度理解也較強。在大量文本解析的訓練下,Sora可以准確捕捉、理解文本指令背後的情感用意,並流暢、自然地將文本提示轉變爲細節豐富、場景匹配的視頻內容。
Sora在視頻生成中可以較好地模擬一個虛擬世界的物理規律,更好的理解物理世界,從而產生真實的鏡頭感。其技術特點主要有二:
一是能多鏡頭生成連貫的三維空間運動視頻。
二是能保持同一物體在不同視角鏡頭下的一致性。以此,模型能保持視頻中人物、物體、場景的運動連貫性和持續性,並可以通過微調對世界中的元素產生影響,進行簡單互動。對比此前的Pika等模型,Sora生成視頻還可以對視頻色彩風格等要素精確理解,創造出人物表情豐富、情感生動的視頻內容。且注重主體和背景的關系,使視頻主體與背景的互動高度流暢、穩定,分鏡切換符合邏輯。
在官方給出的一則生成視頻的例證中:“一位時尚女性走在東京的街道上,街道上到處都是暖色調的霓虹燈和動畫城市標志。她身穿黑色皮夾克、紅色長裙和黑色靴子,手拿黑色皮包。她戴着太陽鏡,塗着紅色脣膏。她走起路來自信而隨意。街道潮溼而反光,與五顏六色的燈光形成鏡面效果。許多行人走來走去”,Sora做到了完全細致細節的描述,甚至到皮膚細節描繪,且對於光影反射運動方式、鏡頭移動等細節處理都具備真實感。

2、Sora處於什么水平?還有哪些局限?
Sora相當於語言類模型的ChatGPT3.5,是業內重大突破,處於非常領先水平,但還是有其本身的局限性。
Sora和ChatGPT同源與Transformer架構,前者在架構基礎上搭建了擴散模型,在展示深度、物體永久性和自然動力學方面十分出色。之前的真實世界模擬通常是用GPU驅動的遊戲引擎來進行三維物理建模來運行,需要人爲搭建且過程復雜,精准度也高,能實現高標准的環境模擬和各種交互動作。但Sora模型沒有數據驅動的物理引擎和圖形編程,在更高要求的三維搭建中准確度低。因此,實現多個角色自然交互並與環境進行逼真的模擬仍然很困難。
例如,舉兩個Sora生成視頻出現bug的例子:
當Sora輸入的文本是“一個被打翻了的玻璃杯濺出液體來”時,顯示的是玻璃杯融化成桌子,液體跳過了玻璃杯,但沒有任何玻璃碎裂效果。
再比如,從沙灘裏突然挖出來一個椅子,而且AI認爲這個椅子是一個極輕的物質,以至於可以直接飄起來。

出現這類“錯誤”的原因主要有兩點:
一是因爲模型在自動補齊生成中內容,自發地產生了不在文本規劃內的對象或實體,這種情況尤爲常見,特別是在擁擠或雜亂的場景中。在某些場景中,這會增加視頻的真實感,比如在OpenAI給出的“漫步在冬天日本街頭”的案例中,但在更多環境中這會降低物理規律在視頻中的合理性,例如第一個例子中憑空生成的桌子是水變成的。
二是當發生許多動作在Sora的模擬中時,很容易混淆順序,包括時間順序與空間順序。例如,當輸入“跑步機上跑步的人”時它有幾率會生成一個在跑步機上向錯誤方向行走的人。因此Sora准確地模擬更復雜的現實世界物理交互、動態和因果關系,對簡單的物理和物體屬性模擬也仍具有挑战性。
盡管存在這些持續性的問題,但Sora展現了視頻模型未來的潛力,只要有足夠的數據和計算能力,視頻轉換器可能开始更深入地理解現實世界的物理、因果關系。這或許會讓基於視頻的模擬世界訓練AI系統的新方法成爲可能。
3、Sora的發展方向,面臨什么挑战和機遇?
Sora代表視頻生成類AI前沿,但是其未來效能的提升或許可以從三大方向切入:
一是從數據維度入手。隨着訓練的數據需求激增,未來面臨可訓練數據樣本匱乏問題。當前主要大模型依賴於語言文本,雖然Sora也可以進行圖片輸入,但訓練泛度不及文本。數據種類單一且高質量數據有限,在參數量指數級提升的背景下或將快速耗盡。
康納爾大學研究表明,大模型訓練的高質量數據很有可能在2026年前就耗盡,低質量文本數據在2030後耗盡。擴大數據來源的維度是Sora的解法。除文字和圖像外,音頻、視頻、熱能、勢能、深度都能成爲Sora學習的拓展領域。幫助其成爲真正的多模態大模型。例如Meta开源的ImageBind擁有多種感官,不僅具有DINOv2的圖片、視頻識別能力,還擁有紅外輻射和慣性測量單元,能對深度、熱能、勢能等不同模態進行感知學習。Sora在輸入端拓展後也可以將上述維度與視頻生成更好的結合,訓練模擬更真實的物理世界。
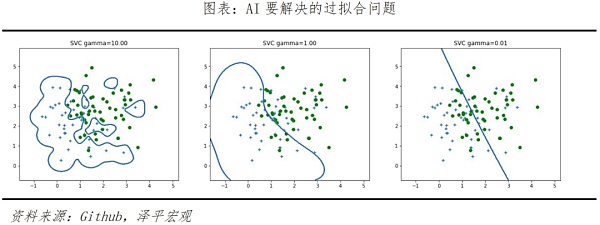
二是從算法層進行優化,解決模型學習中存在的“過擬合”和“欠擬合”現象是關鍵。在前文例子中提到過,Sora會自發地產生不在文本規劃內的對象或實體,這有助於完善視頻效果的真實性。但是,某些情況下兩個高度關聯的元素可能會在不適用的場景下同時出現,也就是算法爲了達到特定結果而出現了“過擬合”。這種現象類似人類在備考中爲了答對一類問題反復強化訓練,反而導致考試中同類問題大量出錯。
而同一個例子中杯子被打翻了卻沒有碎裂效果卻是融化了,則是因爲模型“欠擬合”。模型出現這兩類問題的原因是將並不准確分類的樣本選取進行了訓練,形成的決策樹也就不是最優模型,導致真實應用的泛化表現下降。過擬合和欠擬合無法被徹底消除,但未來可以通過一些方法進行緩解減少,例如:正則化、數據清洗、降低訓練樣本量、Dropout棄用,剪枝算法等。
三是算力產業。Sora持續引爆AI浪潮,這也將導致2024年算力需求將在多模態模型發展下持續高漲,AI企業尋求更大力度的產業鏈上遊切入,向芯片研發設計布局,甚至向EDA和晶圓領域進發。
當下AI模型訓練主要依靠英偉達GPU,但主流算力芯片已經供不應求,預測的到2024年需求將達到150-200萬。
OpenAI創始人Sam Altman從2018年起就重視其芯片供需問題,投資了AI芯片公司Rain Neuromorphics,2019 年購买Rain的芯片,再到2023年11月Sam爲一家代號爲“Tigris”的芯片企業尋求數十億美元融資。作爲行業龍頭,已經在早期布局構建一套由自家領導的算力產業鏈,旨在通過AI產業革命重塑全球半導體格局。
以智能汽車切入AI賽道的特斯拉,也在自動駕駛算法的基本盤上向上遊的芯片設計進發,並在逐漸謀求對中遊的控制。
可以預見的是,由ARM、英偉達、台積電構建的全球AI半導體產業鏈雖然是短期的最大收益者,但在中長期看或迎來更大的競爭。算力基礎設施的自主化建設、尤其是算力芯片,仍是中國在AI賽道上與全球保持同步進步的重要方向。
4、Sora的應用領域,會顛覆哪些行業?
從年初蘋果發布Vision Pro頭戴式顯示設備、到各家PC大廠接連發布AIPC,再到這次的OpenAI發布Sora,全世界對於人工智能的創新在加速,迭代地越來越快。
今後用AI自動創作生成的內容會影響很多的行業領域,對於熱點話題的“時效性覆蓋”將主要是AI的任務,比拼的主要是AIGC的效率,比拼的是大家能夠駕馭AI的能力,比拼的是誰能夠駕馭類似於Sora這種強勢能的AI生產工具。以後“扔一部小說、出一部大片”不是不可能了,Sora可以生成長達1分鐘的視頻,視頻可以一鏡到底,多角度鏡頭切換,並且對象始終不變。Sora視頻,更可以運用景物、表情和色彩等鏡頭語言,表達出如孤獨、繁華、呆萌等情感色彩。總之,如果未來出現更多的Sora、或者這些生成視頻大模型從以上所述的幾個角度進行更多的改良滯後,未來的AI視頻效果,或許幾乎和人工拍攝不相上下。
多模態模型的應用在2024將迎來黎明,影響影視、直播、媒體、廣告、動漫、藝術設計等數個行業。在當下的短視頻時代,Sora“一個人”就全包了短視頻的攝影、導演、剪輯等任務。未來,Sora生成的各種不同用途的視頻,對於現在的短視頻、直播、影視、動漫、廣告等行業都會產生深遠影響。
比如,在短視頻創作領域,Sora 有望極大降低短劇制作的綜合成本,解決“重制作而輕創作”的共性問題,短劇制作的重心未來有望回歸高質量的劇本內容創作,考驗的是優秀創作者的構思能力。Sora有望真正爲相關行業的企業降本增效,廣告制作公司通過Sora 模型生成符合品牌的廣告視頻,顯著減少拍攝和後期制作成本;遊戲與動畫公司使用Sora直接生成遊戲場景和角色動畫,減少了 3D模型和動畫制作成本。企業節省下來的成本可以用於提高產品、服務質量或者技術創新,推動生產力進一步提升。如果說2023年是全球AI大模型大爆發,是圖文生成元年的話,那2024年行業會進入AI視頻生成和多模態大模型元年。從Chatgpt到Sora,AI對每個個人、每個行業的現實影響與改變正在逐步發生。
標題:Sora橫空出世 會顛覆哪些行業?
地址:https://www.coinsdeep.com/article/95956.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。