半年多過去了 ChatGPT的排名快“墊底”了
發表於 2023-09-09 11:00 作者: 元宇宙之心
作者:三言科技
今天,筆者無意中刷到一張圖片。
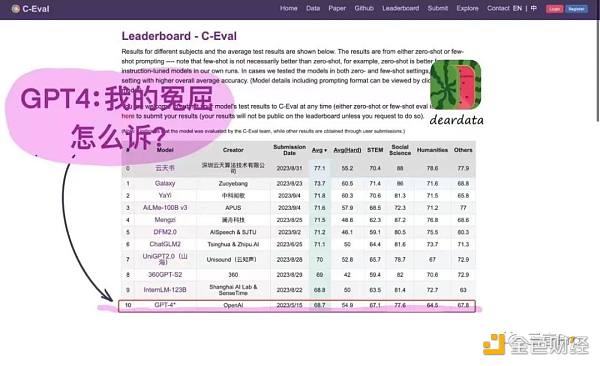
據該圖片顯示,OpenAI的GPT-4在11個大模型中(第一名序號爲0),已經排到了最後。還有網友配上了“GPT4:我的冤屈怎么訴?”的字樣。
這不禁讓人好奇,今年年初,ChatGPT爆火以後,其他公司才开始提大模型的概念。
這才半年多,GPT就已經“墊底”了?
於是,筆者想看看GPT排名到底咋樣了。
測試時間不同 測試團隊不同 GPT-4排第十一
從前文中圖片上顯示的信息來看,這個排名是出自C-Eval榜單。
C-Eval榜單,全稱C-Eval全球大模型綜合性考試測試榜,是由清華大學、上海交通大學和愛丁堡大學合作構建的中文語言模型綜合性考試評估套件。
據悉,該套件覆蓋人文、社科、理工、其他專業四個大方向,包括52個學科,涵蓋微積分、线性代數等多個知識領域。共有13948道中文知識和推理型題目,難度分爲中學、本科、研究生、職業等四個考試級別。
於是筆者查看了最新的C-Eval榜單。
C-Eval榜單的最新排名與前文中圖片所顯示的排名相符,排名前十一的大模型中,GPT-4排最後。
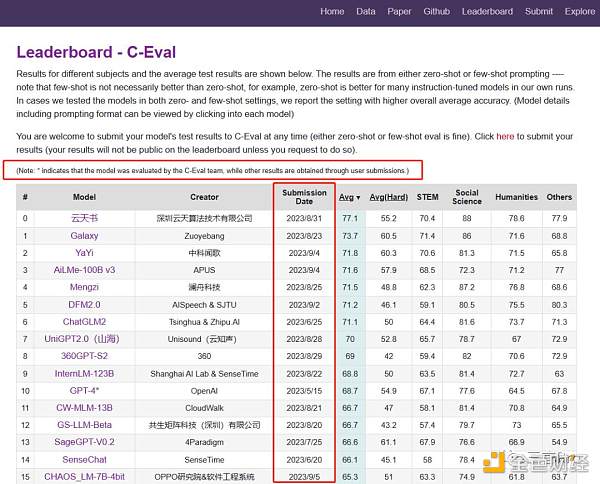
據C-Eval榜單介紹,這些結果代表zero-shot(零樣本學習)或者few-shot(少樣本學習)測試,但few-shot不一定比zero-shot效果好。
C-Eval表示,在其測試中發現許多經過指令微調之後的模型在zero-shot下更好。其測試的很多模型同時有zero-shot和few-shot的結果,排行榜中顯示了總平均分更好的那個設置。
C-Eval榜單還注明了,大模型名字中帶“*”的,表示該模型結果由C-Eval團隊測試得到,而其他結果是通過用戶提交獲得。
此外,筆者還注意到,這些大模型提交測試結果的時間有很大差別。
GPT-4的測試結果提交時間是5月15日,而位居榜首的雲天書,提交時間爲8月31日;排第二的Galaxy提交時間爲8月23日;排第三的YaYi提交時間爲9月4日。
並且,排名前16的這些大模型,只有GPT-4的名字加了“*”,是由C-Eval團隊測試的。
於是筆者又查看了完整的C-Eval榜單。
最新的C-Eval榜單一共收錄了66個大模型的排名。
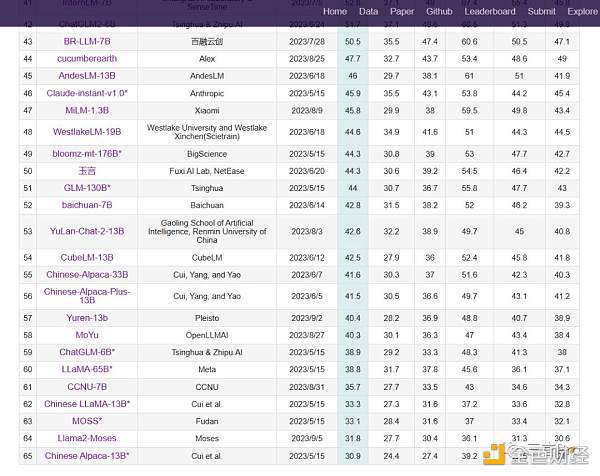
其中,名字帶“*”,也就是由C-Eval團隊測試的,只有11個,且提交測試的時間均爲5月15日。
這些由C-Eval團隊測試的大模型,OpenAI的GPT-4排第十一,ChatGPT排第三十六,而清華智譜AI的ChatGLM-6B排在第六十,復旦的MOSS排在了第六十四。
雖然這些排名可以看出國內的大模型發展勢頭的迅猛,但筆者認爲,畢竟不是同一團隊在同一時間進行的測試,不足以完全證明這些大模型誰強誰弱。
這就好比,一個班的學生,每個人的考試時間不同,答的試卷也都不一樣,怎么能靠每個學生的分數比高低呢?
大模型开發者怎么說?多家表示在中文等能力上超過ChatGPT
最近,大模型的圈子相當熱鬧。
又是百度、字節等8家公司大模型產品通過了《生成式人工智能服務管理暫行辦法》備案,可正式上线面向公衆提供服務。又是其他公司相繼發布自家大模型產品。
那這些大模型的开發者又都是怎么介紹自家產品的呢?
7月7日,在2023世界人工智能大會“大模型時代的通用人工智能產業發展機遇以及風險”論壇上,復旦大學計算機科學技術學院教授、MOSS系統負責人邱錫鵬表示,復旦對話式大型語言模型MOSS在今年2月發布後,還在連續不停地迭代,“最新的MOSS已經能夠在中文能力上超過ChatGPT。”
7月底,網易有道上线翻譯大模型,網易有道CEO周楓公开表示,在內部的測試中,在中英互譯的方向上,已經超越ChatGPT的翻譯能力,也超過了谷歌翻譯的水准。
8月下旬,在2023年亞布力論壇夏季高峰會上,科大訊飛創始人、董事長劉慶峰發表演講時稱,“訊飛星火大模型的代碼生成和補齊能力已經超過了ChatGPT,其他各項能力正在快速追趕。當前代碼能力的邏輯、算法、方法體系、數據准備已就緒,所需要的就是時間和算力。”
商湯近期的新聞稿中稱,今年8月,新模型internlm-123b完成訓練,參數量提升至1230億。在全球51個知名評測集共計30萬道問題集合上,測試成績整體排名全球第二,超過gpt-3.5-turbo以及meta公司新發布的llama2-70b等模型。
據商湯介紹,internlm-123在主要評測中,有12項成績排名第一。其中,在評測集綜合考試中的agieval分數爲57.8,超越gpt-4位列第一;知識問答commonsenseqa的評測分數爲88.5,排名第一;internlm-123b在閱讀理解的五項評測中成績全部居榜首。
此外,在推理的五項評測中成績排名第一。
本月初,作業幫正式發布自研銀河大模型。
作業幫表示,銀河大模型在C-Eval、CMMLU兩大權威大語言模型評測基准的成績。數據顯示,作業幫銀河大模型以平均分73.7分位居C-Eval榜首;同時在CMMLU榜單Five-shot和Zero-shot測評中分別以平均分74.03分及73.85分位列第一,成爲首個同時在上述兩大權威榜單平均分排名第一的教育大模型。
昨天,百川智能宣布正式开源微調後的Baichuan 2-7B、Baichuan 2-13B、Baichuan 2-13B-Chat與其4bit量化版本。
百川智能創始人、CEO王小川稱,經過微調之後的Chat模型,在中文領域,在Q&A問答環境,或者摘要環境裏面,評價它的實際性能已經超過ChatGPT-3.5這樣的閉源模型。
今天,在2023騰訊全球數字生態大會上,騰訊正式發布混元大模型。騰訊集團副總裁蔣傑稱,騰訊混元大模型中文能力已經超過GPT-3.5。
除了這些开發者的自我介紹,也有一些媒體和團隊對一種大模型進行評比。
8月上旬,清華大學新聞與傳播學院教授、博士生導師沈陽所在團隊發布了《大語言模型綜合性能評估報告》。報告顯示,百度文心一言在三大維度20項指標中綜合評分國內領先,較優於ChatGPT,其中中文語義理解排名靠前,部分中文能力較優於GPT-4。
8月中旬,有媒體報道稱,8月11日,小米大模型MiLM-6B現身C-Eval、CMMLU大模型評測榜單。截至當前,MiLM-6B在C-Eval總榜單排名第10、同參數量級排名第1,在CMMLU中文向大模型排名第1。
8月12日,天津大學發布《大模型評測報告》。報告顯示,GPT-4和百度文心一言相較於其他模型綜合性能顯著領先,兩者得分相差不大,處於同一水平。文心一言已經在大部分中文任務中實現了對ChatGPT的超越,並逐步縮小與GPT-4的差距。
8月下旬,有媒體報道稱,快手自研的大語言模型“快意”(KwaiYii)已开啓內測。在最新的CMMLU中文向排名中,快意的13B版本KwaiYii-13B同時位列five-shot和zero-shot下的第一名,在人文學科、中國特定主題等方面較強,平均分超61分。
通過上述內容可以看出,這些大模型雖然紛紛號稱自己在某排名中居首,或者是在某某方面超越ChatGPT,但大多是在一些具體的領域表現優異。
另外,有一些綜合評分超過了GPT-3.5或GPT-4,但GPT的測試是停留在5月的,誰能保證這近3個月的時間裏,GPT沒有進步呢?
OpenAI的處境
根據瑞銀集團2月的一份報告顯示,在ChatGPT推出僅兩個月後,它在2023年1月末的月活用戶已經突破了1億,成爲史上用戶增長速度最快的消費級應用程序。
但ChatGPT的發展也不是那么順利。
今年7月,有不少GPT-4用戶吐槽,與之前的推理能力相比,GPT-4的性能有所下降。
有些用戶在推特以及OpenAI在线开發者論壇上指出了問題,集中於邏輯變弱、更多錯誤回答、無法跟蹤提供的信息、難以遵循指令、忘記在基本軟件代碼中添加括號,只能記得最近的提示等等。
8月,又有一份報告稱,OpenAi可能處於潛在的財務危機中,可能於2024年底破產。
報告中表示,OpenAI僅運行其人工智能服務ChatGPT每天就要花費約70萬美元。目前,該公司正試圖通過GPT-3.5和GPT-4實現盈利,但是還尚未產生足夠的收入實現收支平衡。
不過,OpenAI或許也有新的轉機。
日前,OpenAI宣布,將於11月舉辦首屆开發者大會。
雖然OpenAI表示不會發布GPT-5,但OpenAI稱將有來自世界各地的數百名开發人員與OpenAI團隊一起,提前一覽“新的工具”,並且交流想法。
這可能意味着,ChatGPT已經取得了新的進步。
另據澎湃新聞報道,8月30日,一位知情人士透露,通過銷售AI軟件和驅動其運行的計算能力,OpenAI預計將在未來12個月內實現超過10億美元的收入。
今天,又有媒體報道稱,本月晚些時候摩根士丹利將推出一款和OpenAI共同研發的生成式人工智能聊天機器人。
和摩根士丹利的銀行家打交道的人,非富即貴。如果這款即將推出的生成式人工智能聊天機器人能給摩根士丹的客戶帶來不同的體驗,對OpenAI來說,也許會是一個巨大的收獲。
人工智能時代的到來,已經勢不可擋。至於到底誰更勝一籌,不能光靠自己說,還得讓用戶來打分。我們也相信國內大模型一定會、一定能在各具體能力、綜合能力上趕超ChatGPT。
標題:半年多過去了 ChatGPT的排名快“墊底”了
地址:https://www.coinsdeep.com/article/42418.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。