ChatGPT的Web3.0安全審計藝術:有點東西 但是······
發表於 2023-02-24 13:49 作者: CertiK中文社區

2022年11月,OpenAI推出了創新的人工智能(AI)項目。
除了可用於進行文章的撰寫和總結、笑話和詩歌的創作以外,ChatGPT還可以用來調試和生成代碼。
2022年全年,Web3.0領域因黑客攻擊和欺詐等事件造成的資產損失超過了37億美元,這樣巨額損失不禁讓業內人思考:如ChatGPT這樣的新技術是否可以用以改善智能合約代碼的安全性。
ZKasino是一個去中心化的博彩平台,近期通過ChatGPT進行了一次預審計。
ZKasino希望在CertiK开展全面審計的同時,讓CertiK爲ChatGPT所得出的結果進行一個初步的審查,以測試ChatGPT作爲AI「智能合約審計師」的能力。
那么ChatGPT的測試結果如何呢?
其是否已經准備好接替人工代碼審計專家的工作?
或者說它仍不足以完全替代人工?
2022年12月23日,ZKasino「聘請」了ChatGPT來識別智能合約中潛在的安全風險。該工具也的確提出了幾個表面上聽起來很合理的風險擔憂。
然而,盡管ChatGPT不可否認地爲Web3.0安全社區提供了一些有價值的服務,但是我們發現其仍有相當大的改進空間——ChatGPT遺漏了一些嚴重或關鍵性的漏洞,同時又「誤傷」了那些沒問題的代碼。在此,我們希望CertiK安全專家的深度數據和建議能夠助力ChatGPT成爲一個更強大的Web3.0應用安全工具。
下文,我們將爲大家詳細介紹此次事件中ChatGPT的兩類錯誤發現。
ChatGPT發現了合約中的哪些問題?

ChatGPT遺漏了什么
嚴重或關鍵性的漏洞?
ChatGPT提到了在許多智能合約實現中都會存在的幾個常見安全問題。
但是,它未能識別某些嚴重的風險,包括:
項目特定的邏輯漏洞
不准確的數學計算和統計模型
代碼實現和項目設計的不一致
漏洞#1:項目特定的邏輯問題
ChatGPT未能識別出一個關鍵漏洞,該漏洞會導致攻擊者可以不斷地贏取並耗盡Bankroll合約中用戶的資金。玩家可以通過調用可驗證隨機函數(VRF)加入遊戲,Chainlink的VRF會使用隨機數觸發fulfillRandomWords()函數以完成遊戲。
ZKasino的代碼允許用戶在fulfillRandomWords() 調用失敗的情況下將資金取回。
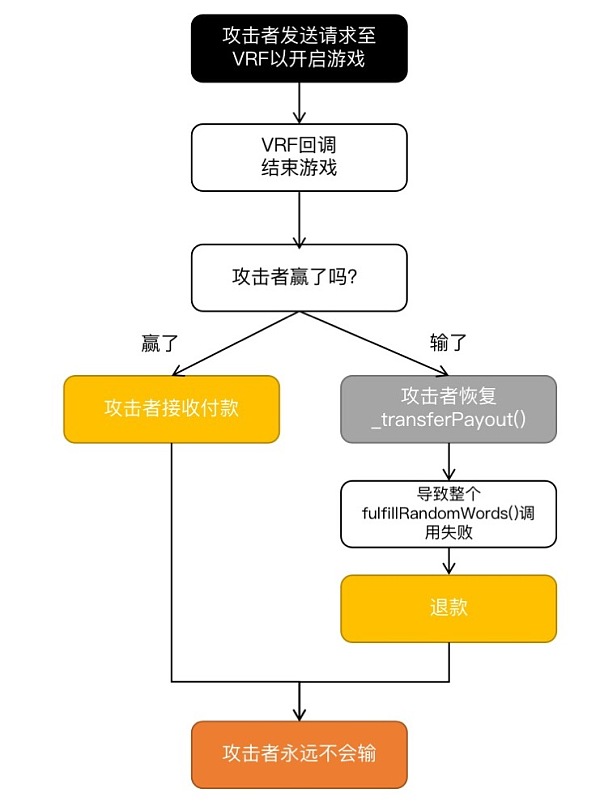
在CertiK對同一智能合約代碼的審查中,發現了一個潛在且有害的_transferPayout()調用,該函數被設計爲可將贏取的資金轉移至玩家的账戶。
然而攻擊者可以在輸了的時候調用_transferPayout()使其回滾,導致整個fulfillRandomWords()調用失敗——這會使其進入長爲100個區塊的等待期,繼而觸發CoinFlip_Refund()進行退款,這意味着攻擊者相當於永遠不會輸錢。
雖然ChatGPT認識到了調用失敗的問題,但卻未能發現在這個項目中利用調用失敗的攻擊手法。
因此,ChatGPT沒有發現該漏洞與項目邏輯相結合所產生的影響。有關具體攻擊流程的描述,請參閱ZKasino的完整審計報告。
漏洞#2:不准確的數學計算和統計模型
確保滿足合理預期的隨機性和結果在任何遊戲項目中都至關重要。爲了證實這一點,需要在審計過程中對所有遊戲結果的隨機性進行全面評估。
盡管ChatGPT同樣「認同」這一點的重要性,但它並未發現任何不公平的遊戲結果。它提出了VRF的使用,以及如果VRF合約被破壞或被操縱,可能會出現不公平的結果:
“如果VRF合約不安全或被操縱,則可能會導致遊戲出現不公平的結果。”
然而,這個結論僅僅只是一個結論,並沒有真正解決導致遊戲結果不公平的根本原因。而且我們在審計過程中也發現了一些關於隨機性的潛在風險問題。
不公平的隨機性
發現的其中一個關於隨機性的中等級別風險是VideoPoker遊戲中不公平的隨機數使用問題,玩家獲得某些牌的機會較少。
小數截斷
另一個風險問題是在骰子類遊戲中發現的,它允許玩家選擇特定的倍數來使他們的預期收益最大化。
漏洞#3:代碼實現和項目設計的不一致
ChatGPT往往能夠理解單一函數的實現,卻無法理解這樣寫的根本原因。
例如,它可能了解某個函數在技術層面是怎樣執行的,但他無法理解在整個智能合約中,該函數有着什么樣的目的。
爲了確保ChatGPT在編碼中不出問題,它需要更好地理解智能合約的代碼邏輯。
就目前的情況而言,ChatGPT提供的是對代碼的表面閱讀。爲了使其審計工作和水平更上一層樓,它必須學會從一個函數反向推導出其初始邏輯——這點非常重要。
不正確的輸入驗證
我們在Plinko合約中發現了一個輸入驗證問題,導致倍數設置不正確。
根據ZKasino的說法,Plinko中使用的行數應該是8到16。但是,由於以下檢查中的錯誤,Bankroll合約所有者可以通過函數setPlinkoMultipliers()設置一個超出預期範圍的行數值。
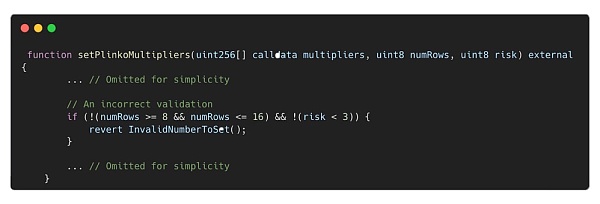
代碼顯示,如果numRows和risk均不滿足條件,該流程將被回滾。
但是,如果兩個條件中只有一個不滿足,那么檢查仍然會通過,並且代碼不會被回滾。
ChatGPT在回答第二個問題時給出了不同的答案:該函數檢查“numRows”的值是否在8到16之間,以及“risk”的值是不是小於3。如果不滿足上述任一條件,函數將返回錯誤“InvalidNumberToSet”。
ChatGPT似乎理解了這個函數的目的。然而,它並不具備相應的應用程序知識,在沒有額外信息的情況下也無法識別真正的漏洞。
值更新的不一致
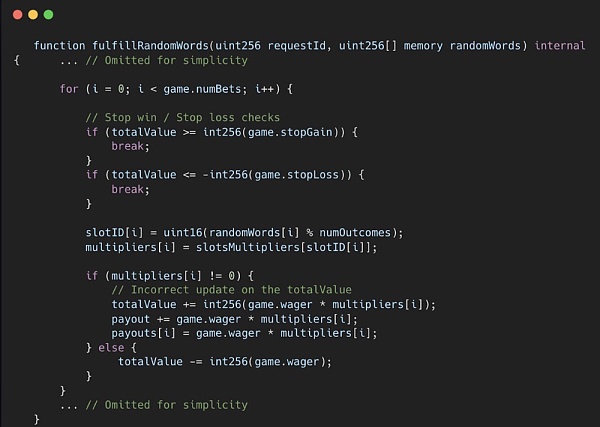
在Slots合約中,發現了與totalValue更新不一致相關的問題,這可能導致遊戲過早結束。totalValue用於監控用戶的輸贏,但它只跟蹤了支付情況,卻未從實際遊戲中扣除,導致用戶的損益計算錯誤。
寫在最後
盡管經過了相應培訓,但ChatGPT在其審計中還是遺漏了某些關鍵性的安全問題。這是由於人工智能在充分理解代碼的復雜性和細微差別方面的局限性,以及其缺乏在現實場景中的實踐經驗。
正如其官網所述,ChatGPT是一個依賴自然語言處理進行對話的研究版本。它通常無法像人類審計專家那樣去理解代碼背後的意圖和邏輯推理。
因此,重要的是需要通過經驗豐富的安全專家的手動審計來補充ChatGPT分析的不足之處,以確保全面的准確性。
下圖強調了基於人工的服務以及ChatGPT在各種標准上的優勢和劣勢。

就像是我們使用百度翻譯一樣,英文翻譯結果的准確性往往取決於我們的中文措辭——ChatGPT回答的有效性在很大程度上取決於prompt(prompt是 javascript語言中的一個方法,主要用處是顯示提示對話框)的格式。
在本文中,我們將ZKasino與ChatGPT交互的預審計結果和CertiK專家執行的最終審計結果進行了比較。
隨着技術的進步和對prompt工程的更清晰的理解,工程師將能夠更好地利用 ChatGPT。
在CertiK官方公衆號接下來發布的內容中,我們將會就如何向ChatGPT提出有效問題來與大家探討prompt工程的更多深入性內容。
但是現在,ChatGPT甚至已經可以幫助我們參加奪旗比賽了:【我讓AI來幫我寫文章、分析代碼,甚至參加了CTF奪旗比賽!】歡迎大家點擊閱讀!
標題:ChatGPT的Web3.0安全審計藝術:有點東西 但是······
地址:https://www.coinsdeep.com/article/10750.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。