谷歌AI繪畫4大牛攜手創業 天使估值7個億
發表於 2023-03-05 15:00 作者: Defi之道

圖片來源:由無界版圖AI工具生成
最近的谷歌像個大漏勺,這不,又有AIGC核心成員聯手跑路咯!
量子位獨家獲悉,這回跟谷歌say byebye的,是文生圖核心團隊——AI繪畫模型Imagen論文的四位核心作者,出走目的是要搞自己的AI公司。雖然公司名稱暫未對外公布,但新公司將一以貫之的路线是很清楚的:
以Imagen爲基礎,沿着原來的項目做下去,不僅繼續做文生圖,還要做視頻方向。
核心人才創業,自然少不了VC塞錢——已經按1億美元的驚人天使估值完成了首輪融資,而且更多VC想給錢而趕不上、投不進。

這也算是文生圖、文生視頻、AIGC賽道上,最知名的研究團隊之一了。
文生圖骨幹成員共創AIGC新公司
新公司聯創四人,Chitwan Saharia、William Chan、Jonathan Ho以及Mohammad Norouzi,都出自谷歌。
他們之前精力重點放在AIGC的文生圖板塊,是谷歌用來對抗DALLE-2的大殺器Imagen的論文共同作者,位置都挺重要的那種。

先來介紹一下Chitwan Saharia,也是Imagen的共同一作。

Chitwan本科畢業於孟买理工學院計算機科學與工程專業,在孟买理工學院和蒙特利爾大學都當過程序和算法方面的研究助理。2019年加入谷歌,base多倫多,花了3年時間從二級軟件工程師做到高級研究科學家,去年12月從谷歌離職。
Chitwan有語音識別、機器翻譯的經驗,在谷歌工作時,主要負責領導image-to-image擴散模型的工作。
第二位William Chan,也是Imagen論文共同一作。他同樣出身計算機工程,先後就讀於加拿大滑鐵盧大學、卡內基梅隆大學,中間在新加坡國立大學當過1年交換生。

在卡內基梅隆大學拿下博士學位後,William還在加拿大最大的社區學院之一喬治布朗學院,主攻烘焙和烹飪(?),學了3年。
Willian從2012年起加入谷歌,於2016年成爲谷歌大腦的一份子,去年5月離職時,他已經是谷歌大腦多倫多的研究科學家了。
然後要介紹的是Jonathan Ho,UC伯克利博士畢業。
他不僅是Imagen論文的core contribution,還是Diffusion Model奠基之作《Denoising Diffusion Probabilistic Models》的一作。

博士畢業於UC伯克利計算機科學專業的Jonathan,之前在OpenAI當過1年的研究科學家,後來在2019年加入谷歌,共工作了2年零8個月,去年11月以研究科學家的身份從谷歌離職。
新公司的最後一位聯創叫Mohammad Norouzi,也是Imagen論文的共同一作。

△
他在多倫多大學計算機科學博士就讀期間,拿到了谷歌ML博士獎學金。畢業後他加入谷歌大腦,在那兒工作了7年,在谷歌的最後title是高級研究科學家,工作重點是生成模型。
同時,Mohammad也是谷歌神經機器翻譯團隊的原始成員,SimCLR的聯合發明人。他在GitHub主頁上小小地透露了自己的最近動態:
目前,我在一家初創公司工作,公司使命是推進人工智能的發展水平,幫助人類提高創造力。我們正在招聘!
這句話以外,關於新公司的更多信息,四人在任何社交平台都沒有更詳細的透露。
這已經是谷歌最近漏出去的第n波人了。
就拿剛剛過去的2個月來說,先是包括顧世翔(Shane Gu,‘讓我們一步一步地思考’研究者)在內的至少4名谷歌大腦成員加入OpenAI;情人節時,Hyung Won Chung和CoT最早的一作Jason Wei攜手組團叛逃OpenAI。
本周三,您猜怎么着?嘿,又跑了一個:
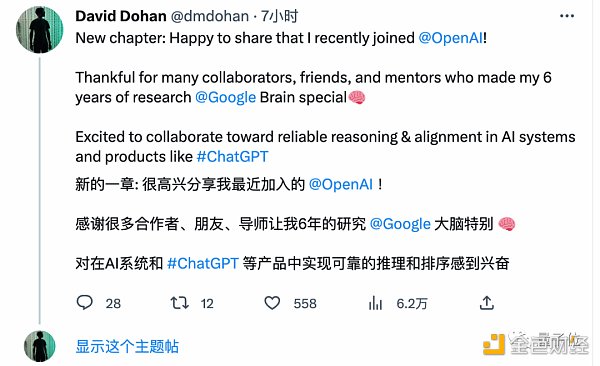
OpenAI狂喜,只有谷歌大漏勺本勺受傷的世界誕生了。
Imagen是什么?
了解完谷歌漏走的這四個人,回頭來說說爲他們職業生涯贏得掌聲的Imagen項目。
Imagen是谷歌發布的文生圖模型,發布時間在DALL-E 2新鮮出爐一個月以後。
本文开頭放的熊貓震驚表情包,就是朝Imagen輸入“一只非常快樂的毛茸熊貓打扮成了在廚房裏做面團的廚師的高對比度畫像,他身後的牆上還有一幅畫了鮮花的畫”後,得出的一張要素完備的AI生成畫作。(不好意思,請自行斷句)

在Imagen出現之前,文生圖都共用一個套路,那就是CLIP負責從文本特徵映射到圖像特徵,然後指導一個GAN或Diffusion Model生成圖像。
Imagen不走尋常路,开闢了text-to-image新範式:
純語言模型只負責編碼文本特徵,具體text-to-image的工作,被Imagen丟給了圖像生成模型。
具體來講,Imagen包含一個凍結的語言模型T5-XXL(谷歌自家出品),當作文本編碼器。T5-XXL的C4訓練集包含800GB的純文本語料,在文本理解能力上比CLIP強不少,因爲後者只用有限圖文對訓練。
圖像生成部分則用了一系列擴散模型,先生成低分辨率圖像,再逐級超採樣。
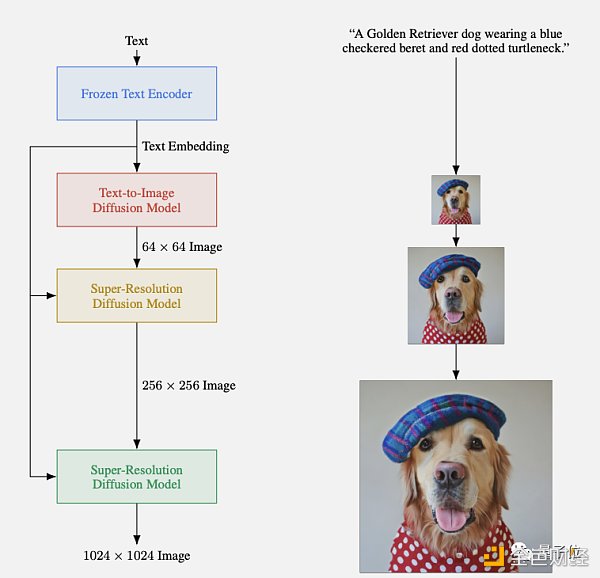
依賴於新的採樣技術,Imagen允許使用大的引導權重,所以不會像原有工作一樣使樣本質量下降。這么一來,圖像具有更高的保真度,並且能更好地完成圖像-文本對齊。
概念說起來簡單,但Imagen的效果還是令人大爲震撼的。
生成的狗子飆車技術一流:

比起爆火的DALLE-2,Imagen能更准確地理解同時出現兩個顏色要求的情況:

一邊繪畫一邊寫字這種要求,Imagen也成功完成,不僅寫得對,還能加光影魔術手般的煙花特效(不是)。

以及對後來研究更有幫助的是,谷歌通過Imagen的研究,優化了擴散模型。
首先,增加無分類器引導(classifier-free guidance)的權重可以改善圖文對齊,同時卻會損害圖像保真度。
爲了解決這個bug,在每一步採樣時引入動態閾值(dynamic thresholding)這個新的新的擴散採樣技術,來防止過飽和。

第二,使用高引導權重的同時在低分辨率圖像上增加噪聲,可以改善擴散模型多樣性不足的問題。
第三,對擴散模型的經典結構U-Net做了改進,變成了Efficient U-Net。後者改善了內存使用效率、收斂速度和推理時間。
後來在Imagen上微調,谷歌還推出了能“指哪打哪”版本的文生圖模型DreamBooth。只需上傳3-5張指定物體的照片,再用文字描述想要生成的背景、動作或表情,就能讓指定物體“閃現”到你想要的場景中。
比如醬嬸兒的:

又或者醬嬸兒的:

大概是Imagen效果太過出色,劈柴哥後來親自宣發的谷歌AI生成視頻選手大將,就叫做“Imagen Video”,能生成1280*768分辨率、每秒24幀的視頻片段。
啊,等等,谷歌有Imagen Vedio,這和四人的新公司不是撞方向了嗎?
仔細看了下論文,無論是Imagen還是Imagen Video,各自都有大篇幅涉及風險、社會影響力的內容。
出於安全、AI倫理和公平性等方面考慮,Imagen和Imagen Vedio都沒有直接开源或开放API,甚至連demo都沒有。

哪怕市面上出現开源復刻版本,也不是最正宗的味道。
此前就曝出過在谷歌每年的內部員工調查“Googlegeist”中,員工表示對谷歌執行能力不佳的質疑。也許,這四人出走,繼續做Imagen,並做Imagen的視頻版,說不定就是爲了想把項目放到一個更开放的AI環境。
而且這種出走創業,也是熱錢大錢向AIGC洶湧的結果。
所以既然AIGC的創投熱潮已經在太平洋那頭开啓,那應該在太平洋這頭也不會悄無聲息。
或許你已經聽說了一些同樣的大廠出走創業,歡迎爆料說說~~
來源:“量子位”(ID:QbitAI),DeFi之道
作者:衡宇
標題:谷歌AI繪畫4大牛攜手創業 天使估值7個億
地址:https://www.coinsdeep.com/article/11043.html
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
上一篇